Địa chỉ:
Lầu 7 Tòa nhà STA, 618 đường 3/2, Phường Diên Hồng (Phường 14, Quận 10), TP HCM
Giờ làm việc
Thứ 2 tới thứ 6: 8:00 - 17:00
Địa chỉ:
Lầu 7 Tòa nhà STA, 618 đường 3/2, Phường Diên Hồng (Phường 14, Quận 10), TP HCM
Giờ làm việc
Thứ 2 tới thứ 6: 8:00 - 17:00
Trong kỷ nguyên của trí tuệ nhân tạo (AI) và Xử lý ngôn ngữ tự nhiên (NLP), chúng ta thường nghe nhắc đến các mô hình như ChatGPT hay Gemini hiểu được ngôn ngữ con người một cách kinh ngạc. Bí mật đằng sau khả năng đó chính là Embedding. Vậy thực chất Embedding là gì và tại sao nó lại đóng vai trò quan trọng đến thế? Hãy cùng Starttrain tìm hiểu chi tiết qua bài viết dưới đây.
Embedding (nhúng) là một phương thức biểu diễn các thực thể như văn bản, hình ảnh hay âm thanh dưới dạng các điểm tọa độ trong một không gian vector đa chiều và liên tục. Tại không gian này, vị trí của mỗi điểm không phải là ngẫu nhiên mà nó mang những giá trị ngữ nghĩa sâu sắc, giúp các thuật toán máy học (Machine Learning) có thể xử lý và hiểu dữ liệu một cách logic nhất. Về cơ bản, nó chuyển hóa những khái niệm trừu tượng mà con người sử dụng thành những con số mà máy tính có thể tính toán được.
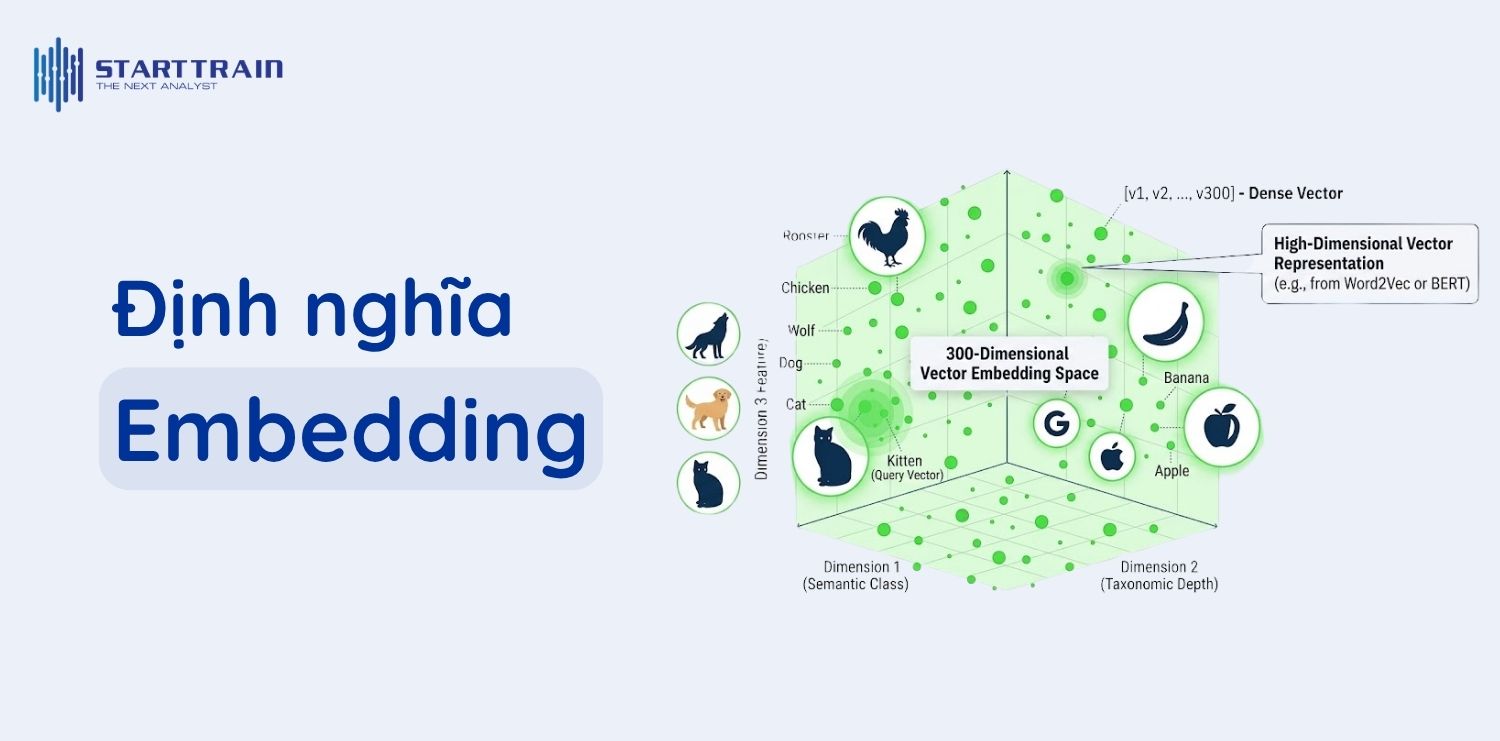
Khác biệt lớn nhất của embedding so với các kỹ thuật lập trình truyền thống là khả năng học trực tiếp từ dữ liệu thông qua các mạng nơ-ron phức tạp thay vì dựa vào các quy tắc do con người thiết lập thủ công. Quá trình này giúp mô hình tự khám phá ra những quy luật ẩn và các mối quan hệ cấu trúc tinh vi trong dữ liệu mà mắt thường hay tư duy con người khó có thể nhận diện được. Điều này tạo nên một bước tiến lớn trong việc giúp máy tính mô phỏng cách con người hiểu thế giới xung quanh.
Bản chất của embedding là giúp máy tính hiểu được ngữ cảnh thay vì chỉ phân tích những từ ngữ hay đối tượng đơn lẻ. Chẳng hạn, nhờ công nghệ embedding của OpenAI, ChatGPT có thể nhận biết được mối liên hệ mật thiết giữa các từ ngữ và các danh mục kiến thức khác nhau.
Điều này cho phép AI tạo ra những phản hồi mạch lạc, tự nhiên và đặc biệt là cực kỳ phù hợp với ngữ cảnh của người dùng. Thông qua việc đo lường khoảng cách giữa các điểm trong không gian toán học, embedding trở thành công cụ đắc lực giúp hệ thống tìm kiếm sự tương đồng và kết nối các thông tin liên quan một cách chính xác nhất.
Embedding đóng vai trò xương sống trong việc giúp trí tuệ nhân tạo (AI) xử lý dữ liệu phi cấu trúc (như ngôn ngữ, hình ảnh, hành vi người dùng). Dưới đây là những lý do tại sao embedding lại cực kỳ quan trọng.
Embedding chuyển đổi các đối tượng phức tạp thành các vector số trong không gian liên tục. Nhờ đó, hệ thống AI không chỉ nhìn thấy các ký tự vô hồn mà còn cảm nhận được sự tương đồng hay khác biệt về mặt ý nghĩa giữa chúng. Điều này giúp mô hình hiểu được sắc thái ngôn ngữ và thực hiện các suy luận logic phức tạp hơn.
Dữ liệu thực tế thường rất khổng lồ và rời rạc. Embedding giúp nén các thông tin này vào một dạng biểu diễn ngắn gọn, súc tích (vector mật độ cao). Quá trình này giúp giảm thiểu đáng kể độ phức tạp khi xử lý dữ liệu lớn, giúp hệ thống hoạt động mượt mà hơn.
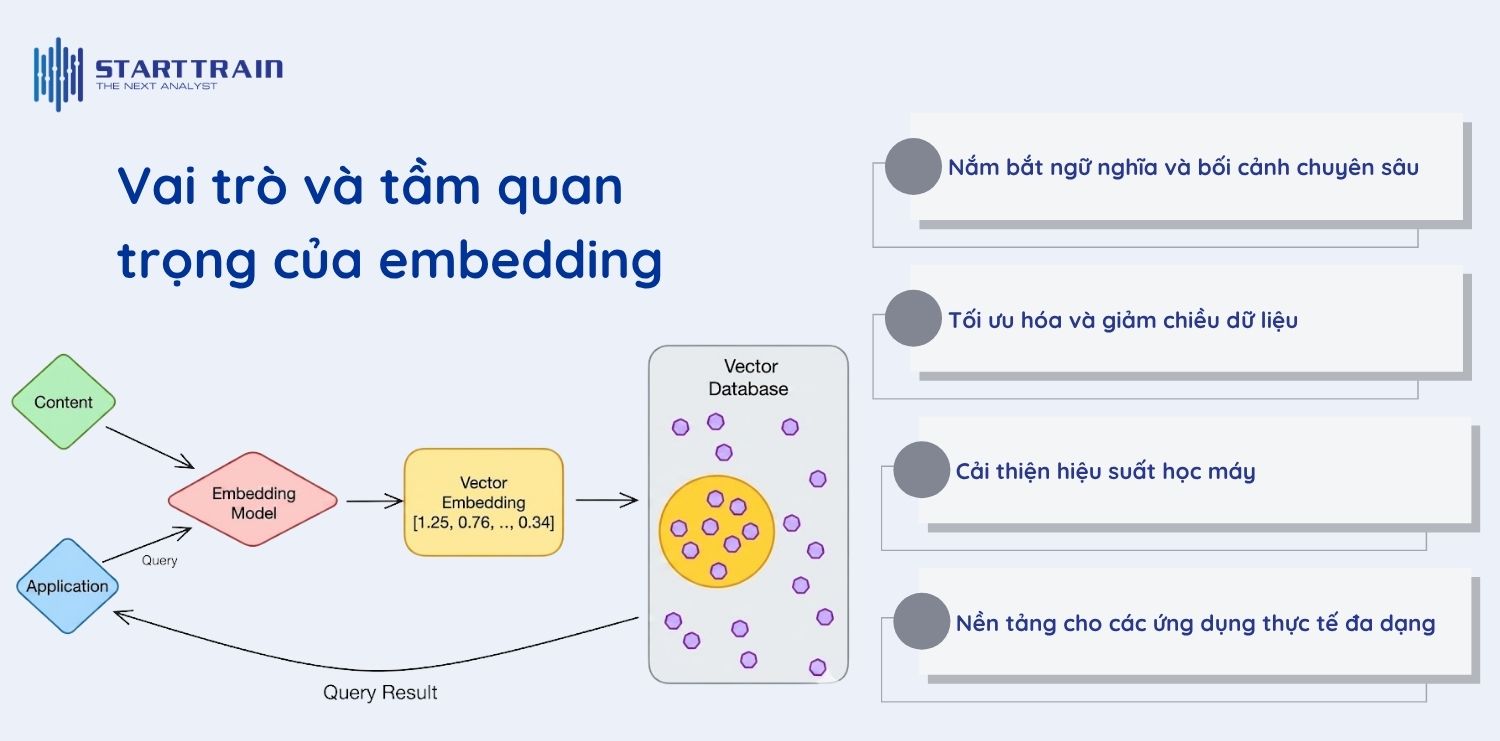
Với cách biểu diễn có cấu trúc và giàu ý nghĩa, các mô hình học máy có thể học nhanh hơn, đạt độ chính xác cao hơn. Embedding giúp mô hình có khả năng tổng quát hóa tốt, tức là có thể xử lý tốt cả những dữ liệu mới mà nó chưa từng gặp trong quá trình huấn luyện.
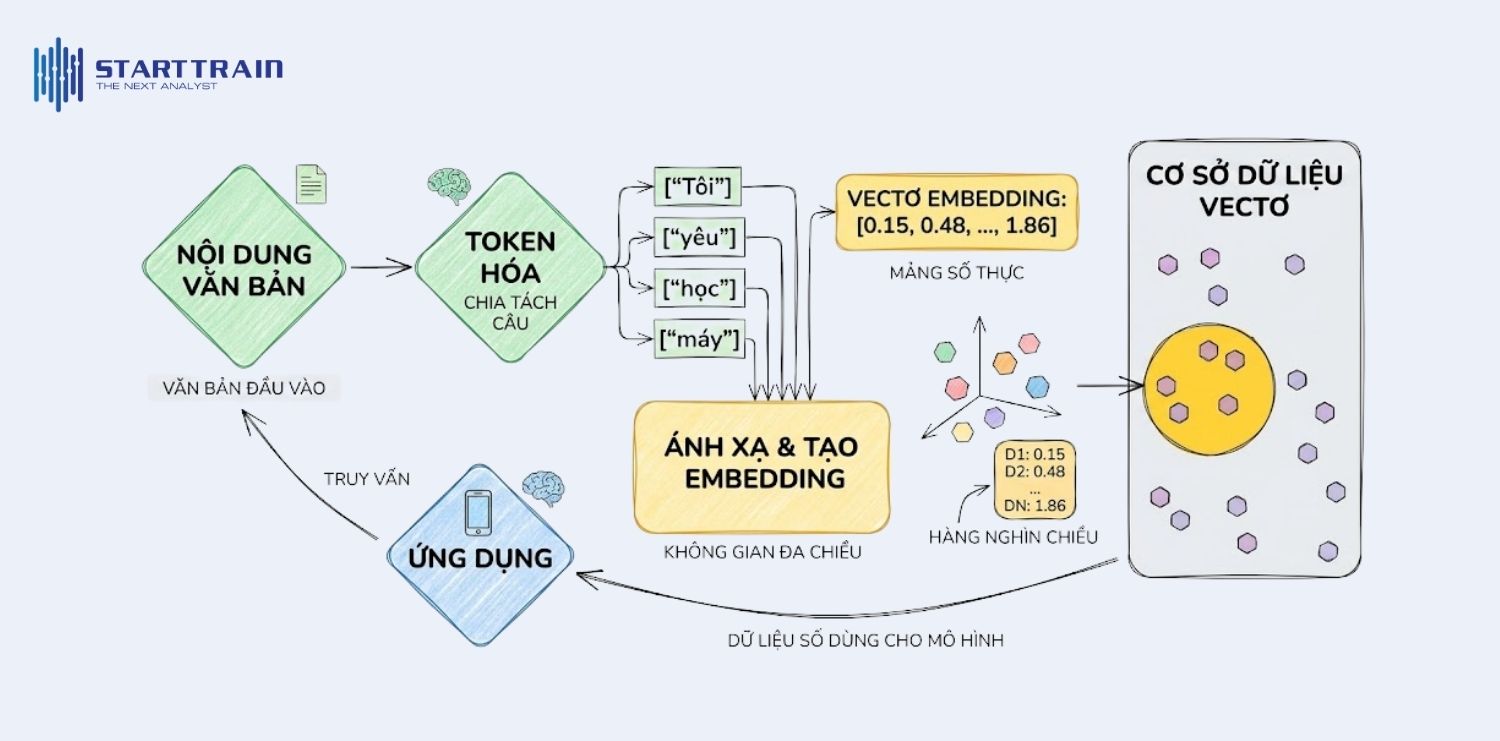
Hầu hết các thuật toán máy học chỉ có thể làm việc với dữ liệu số. Vì vậy, để dạy máy tính hiểu được một từ hay một hình ảnh, chúng ta cần một quy trình chuyển đổi tinh vi để biến dữ liệu thô thành các vector toán học mang tính logic.
Trước khi tạo ra embedding, văn bản cần trải qua bước Token hóa (Tokenization) – tức là chia nhỏ câu thành các đơn vị cơ bản như từ hoặc cụm từ. Ví dụ, câu “Tôi yêu học máy” sẽ được tách thành [“Tôi”, “yêu”, “học”, “máy”].
Sau đó, mỗi token này được ánh xạ vào một không gian đa chiều. Thay vì chỉ gán cho mỗi từ một số thứ tự đơn giản (như 1, 2, 3), hệ thống sẽ tạo ra một embedding vector – một mảng các số thực (ví dụ: [0.15, 0.48, …, 1.86]). Mỗi con số trong mảng này đại diện cho một đặc trưng (dimension) của từ đó trong không gian. Số lượng chiều có thể lên đến hàng nghìn tùy thuộc vào độ phức tạp của mô hình.
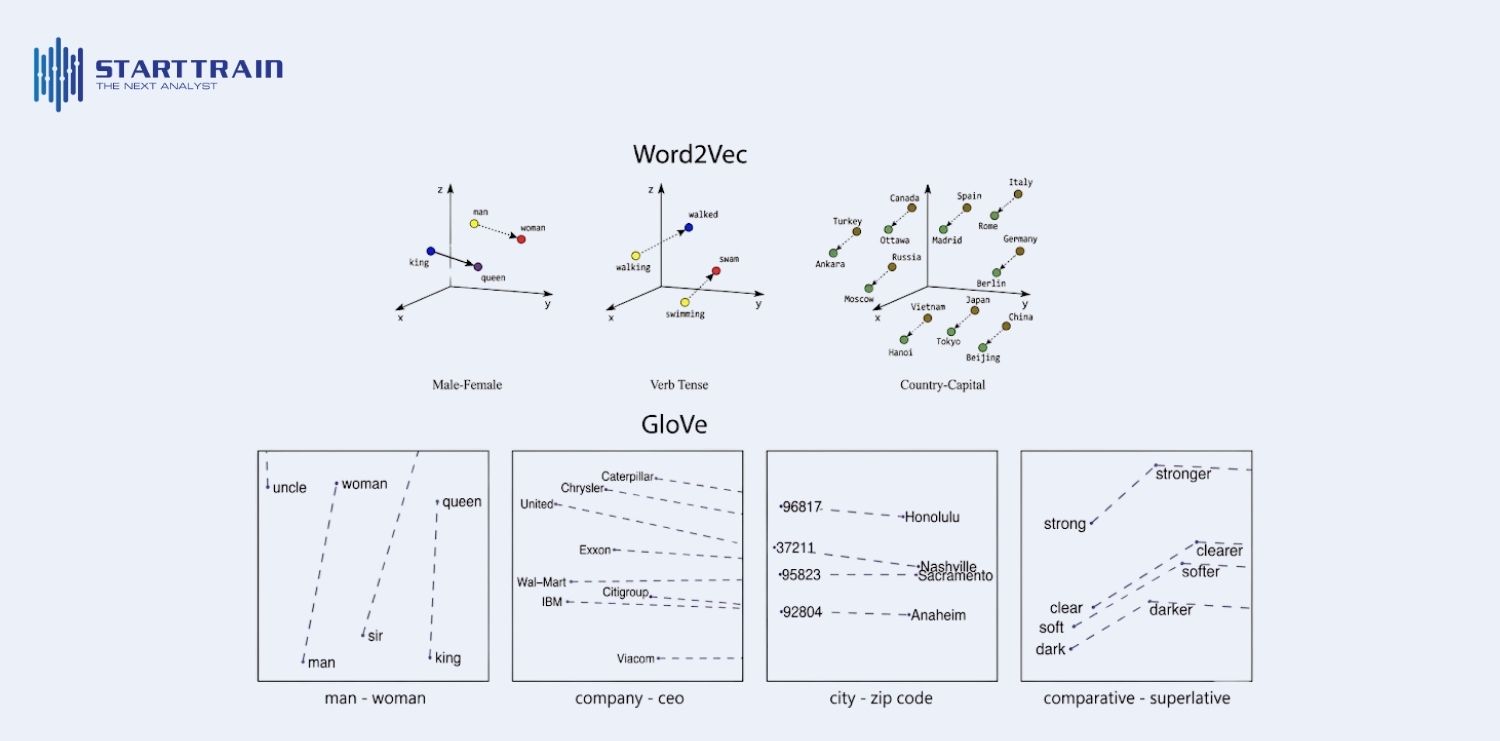
Trong không gian n-chiều này, các đối tượng có sự tương đồng về mặt phân phối hoặc ngữ nghĩa sẽ nằm gần nhau. Hãy lấy ví dụ về hai từ “dad” (bố) và “mom” (mẹ):
Mặc dù có sự khác biệt, nhưng nếu chúng ta vẽ chúng trên một biểu đồ 3D, chúng sẽ tạo thành một cụm (cluster) các từ chỉ quan hệ gia đình. Đặc biệt, từ “father” sẽ nằm cực kỳ gần “dad” so với từ “car” hay “apple”. Sự gần gũi này được đo lường bằng các thuật toán toán học như:
Các mô hình AI hiện đại không sử dụng các con số cố định mà học cách điều chỉnh các vector thông qua quá trình huấn luyện:
Cơ chế này còn cho phép tạo ra các embedding cho người dùng và sản phẩm. Ví dụ, mỗi người dùng và mỗi bộ phim trên Netflix đều có một vector đặc trưng. Hệ thống sẽ tính toán:
RecommendationScore = UserEmbedding x ItemEmbedding
Tích vô hướng càng cao, khả năng người dùng yêu thích bộ phim đó càng lớn. Qua lịch sử tương tác (click, xem, mua), mô hình sẽ liên tục tinh chỉnh các vector này để các gợi ý ngày càng chính xác hơn.
Về mặt kỹ thuật, các embedding thường được tạo ra bằng các mô hình học sâu (Deep Learning) gọi là mạng nơ-ron (neural network). Trong mạng nơ-ron này, một lớp ẩn (hidden layer) sẽ tự động xử lý các đầu vào (như tên một chương trình TV hoặc một từ ngữ) và chuyển đổi nó thành một vector đa chiều dựa trên các thuộc tính khác nhau của đối tượng đó.
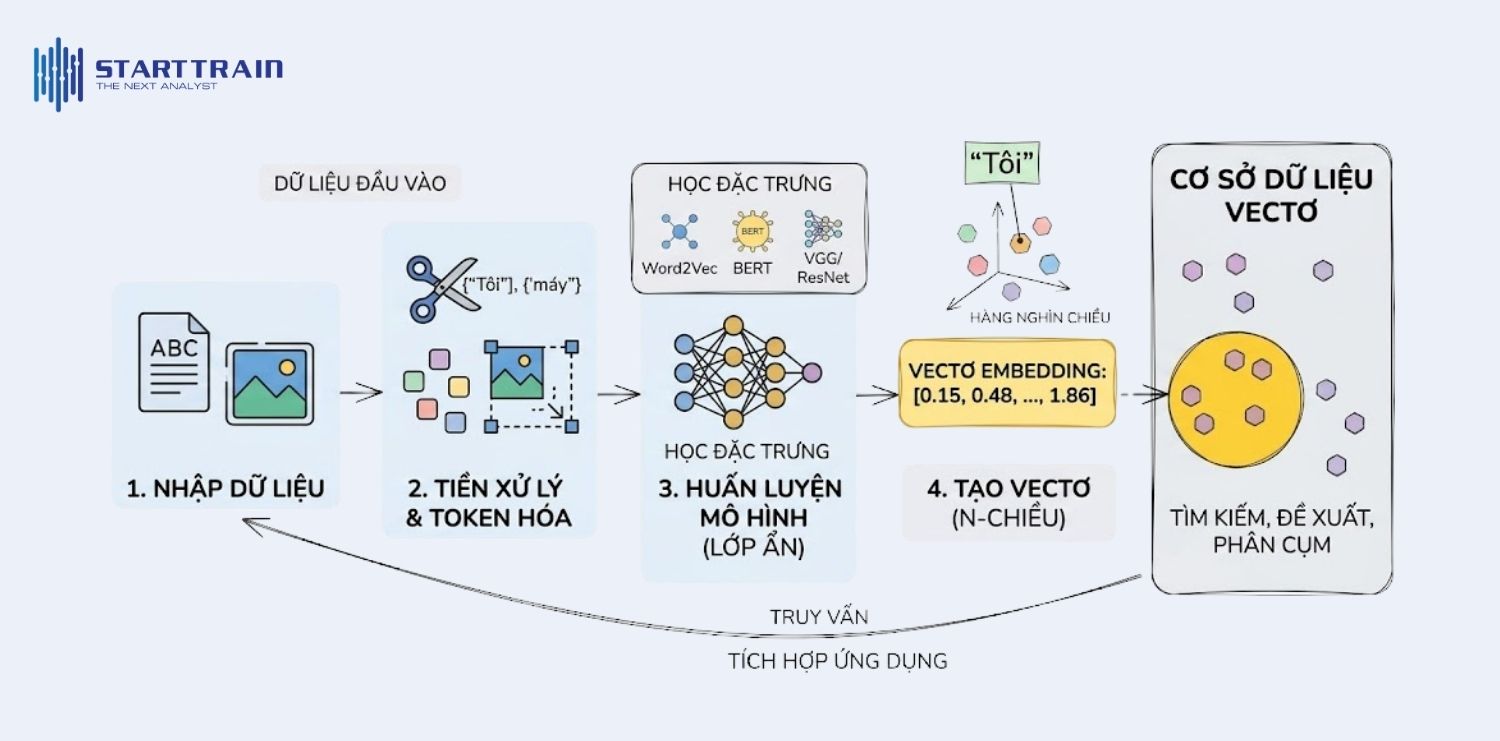
Quy trình tạo ra embedding (hay còn gọi là Embedding Learning) thường tuân theo các bước tổng quát sau:
Dù thường được nhắc cùng nhau trong lĩnh vực AI, nhưng token, vector và embedding đại diện cho các thực thể khác nhau trong quy trình xử lý dữ liệu. Hiểu rõ mối liên hệ này sẽ giúp bạn hình dung được cách “bộ não” nhân tạo vận hành.
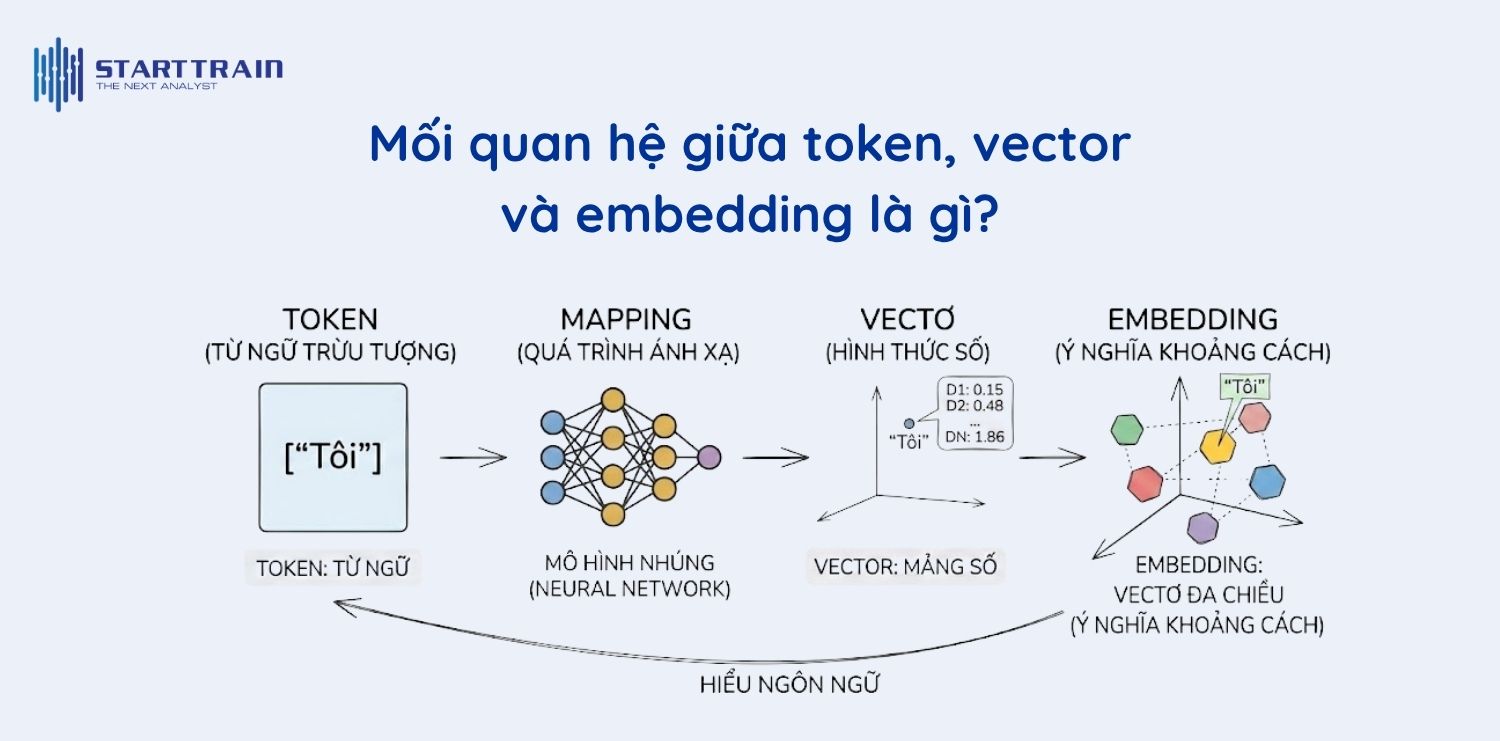
Token là đơn vị cơ bản nhất sau khi văn bản thô được xử lý sơ bộ. Đây là những mảnh nhỏ của ngôn ngữ, có thể là một từ hoàn chỉnh, một phần của từ (subword) hoặc thậm chí là một dấu câu đơn thuần. Token đóng vai trò là đầu vào vật lý, là bước đệm để máy tính bắt đầu quá trình mã hóa thông tin. Nếu không có bước token hóa, AI sẽ chỉ nhìn thấy một dòng ký tự dài vô tận mà không biết đâu là điểm bắt đầu hay kết thúc của một ý nghĩa.
Trong toán học, vector đơn giản là một mảng hoặc một danh sách các con số đại diện cho tọa độ của một điểm trong không gian. Đối với máy tính, vector là cách duy nhất để nó hiểu được thế giới. Một vector có thể đại diện cho bất cứ thứ gì: từ tọa độ GPS, mức độ sáng của một pixel ảnh cho đến giá trị tài chính. Tuy nhiên, một vector thuần túy chưa chắc đã mang tính ngữ nghĩa, nó có thể chỉ là những con số được gán một cách ngẫu nhiên để định danh đối tượng.
Embedding chính là một loại vector đặc biệt. Điểm khác biệt nằm ở chỗ: các con số trong vector embedding được sắp xếp sao cho vị trí của nó phản ánh mối quan hệ nội dung với các đối tượng khác. Trong khi một vector thông thường có thể chỉ là mã số định danh, thì embedding là một tấm bản đồ ngữ nghĩa. Nó cho phép máy tính thực hiện các phép toán trên ý nghĩa, chẳng hạn như nhận biết rằng “trái cam” và “trái quýt” có khoảng cách vector rất gần nhau vì chúng cùng thuộc nhóm trái cây có múi.
Mối quan hệ này vận hành theo một dây chuyền logic: Văn bản gốc được chia nhỏ thành các Token. Mỗi Token này sau đó được ánh xạ vào một Vector số. Qua quá trình học sâu, các Vector này được tinh chỉnh để trở thành các Embedding giàu thông tin ngữ cảnh. Cuối cùng, các mô hình AI như GPT sẽ sử dụng những khối embedding này để tính toán xác suất, hiểu ý định người dùng và tạo ra những câu trả lời mạch lạc nhất.
Tổng kết lại, việc hiểu rõ embedding là gì không chỉ giúp bạn giải mã một khái niệm toán học khô khan mà còn nhận ra đây chính là chiếc cầu nối kỳ diệu giữa ngôn ngữ con người và tư duy của máy tính. Nhờ khả năng chuyển đổi các đối tượng phức tạp thành các tọa độ giàu ngữ nghĩa trong không gian vector đa chiều, embedding đã mở ra cánh cửa cho sự bùng nổ của các mô hình ngôn ngữ lớn (LLMs), hệ thống tìm kiếm thông minh và các thuật toán gợi ý cá nhân hóa.







