Địa chỉ:
Lầu 7 Tòa nhà STA, 618 đường 3/2, Phường Diên Hồng (Phường 14, Quận 10), TP HCM
Giờ làm việc
Thứ 2 tới thứ 6: 8:00 - 17:00
Địa chỉ:
Lầu 7 Tòa nhà STA, 618 đường 3/2, Phường Diên Hồng (Phường 14, Quận 10), TP HCM
Giờ làm việc
Thứ 2 tới thứ 6: 8:00 - 17:00
Trong những năm gần đây, cụm từ LLM đã trở thành tâm điểm của giới công nghệ toàn cầu. Sự bùng nổ của các công cụ như ChatGPT, Claude hay Gemini đã minh chứng cho sức mạnh khủng khiếp của công nghệ này. Vậy cụ thể LLM là gì và tại sao nó lại làm thay đổi cách chúng ta tương tác với máy tính? Hãy cùng Starttrain tìm hiểu chi tiết trong bài viết dưới đây.
LLM là viết tắt của cụm từ tiếng Anh Large Language Model (Mô hình Ngôn ngữ Lớn). Đây là các mô hình học sâu (Deep Learning) với quy mô cực kỳ lớn, được đào tạo trước dựa trên một lượng dữ liệu khổng lồ để hiểu, tóm tắt, dự đoán và tạo ra nội dung văn bản.
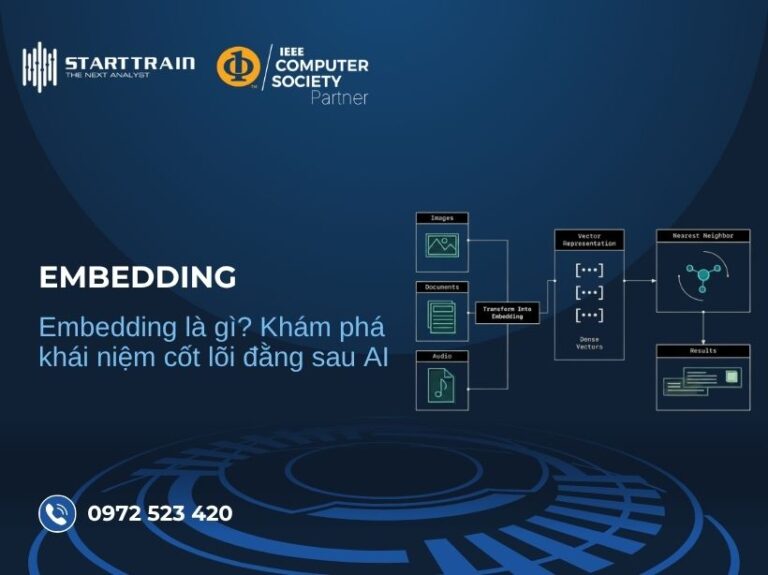
Về mặt kỹ thuật, để hiểu rõ bản chất LLM là gì, chúng ta cần biết về kiến trúc Transformer. Đây là một tập hợp các mạng nơ-ron bao gồm bộ mã hóa (encoder) và bộ giải mã (decoder) với khả năng tự tập trung. Cơ chế này cho phép mô hình trích xuất ý nghĩa từ các chuỗi văn bản và hiểu thấu đáo mối quan hệ phức tạp giữa các từ, cụm từ trong ngữ cảnh của chúng.

Điểm khác biệt giúp LLM vượt trội bao gồm:
Để hiểu được cách các LLM như ChatGPT hoạt động, trước hết chúng ta cần tìm hiểu về cốt lõi của chúng: Kiến trúc Transformer. Đa số các mô hình ngôn ngữ lớn hiện nay đều dựa trên nền tảng này, vốn được Google Brain công bố vào năm 2017 qua bài báo nổi tiếng “Attention Is All You Need”. Chính từ nền tảng này, OpenAI đã phát triển dòng mô hình GPT (Generative Pre-trained Transformer) – hạt nhân tạo nên ChatGPT.
Về cấu trúc, một LLM điển hình bao gồm các thành phần cốt lõi sau:
Kiến trúc này đóng vai trò điều phối dòng chảy thông tin, chia làm hai phần chính:
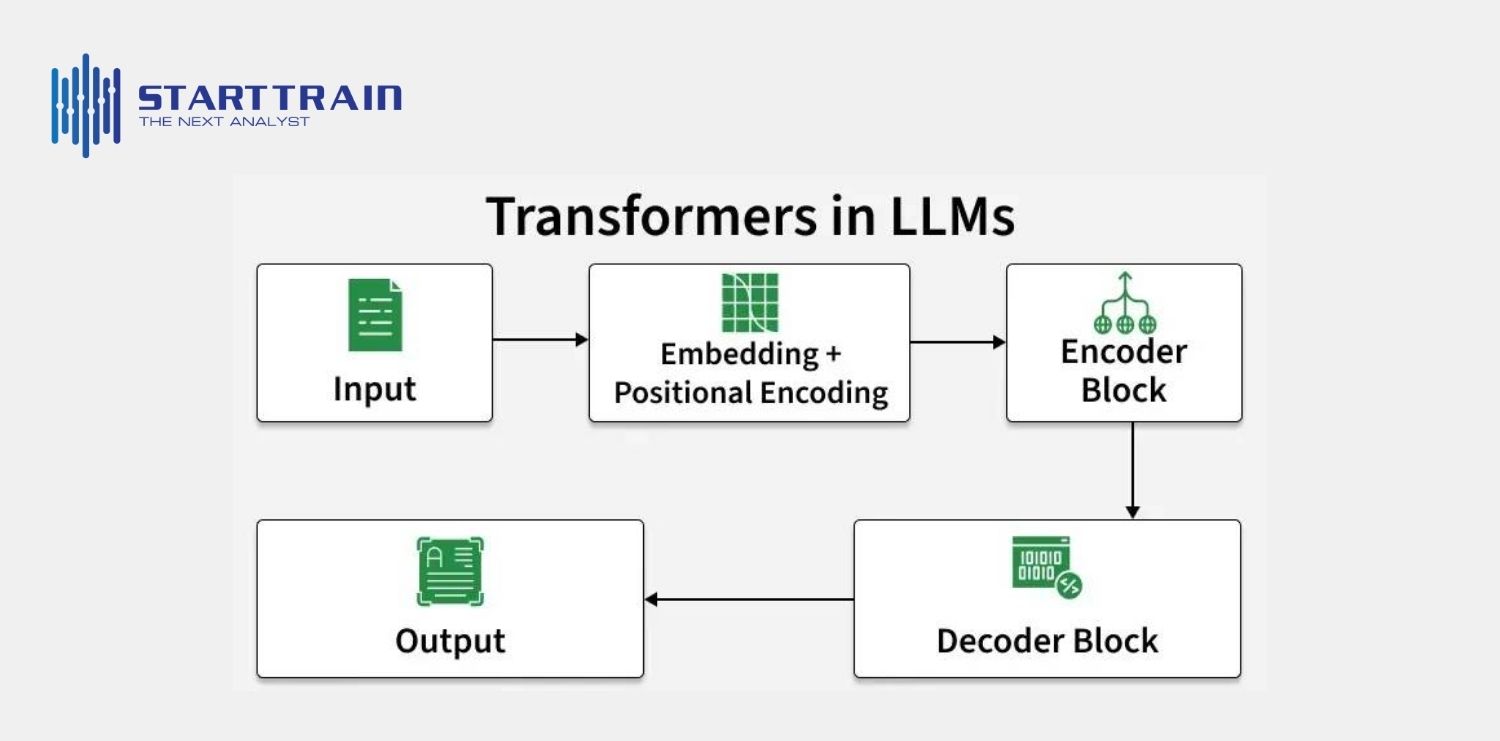
Bên trong một mô hình LLM là sự phối hợp nhịp nhàng của nhiều lớp mạng để xử lý văn bản:
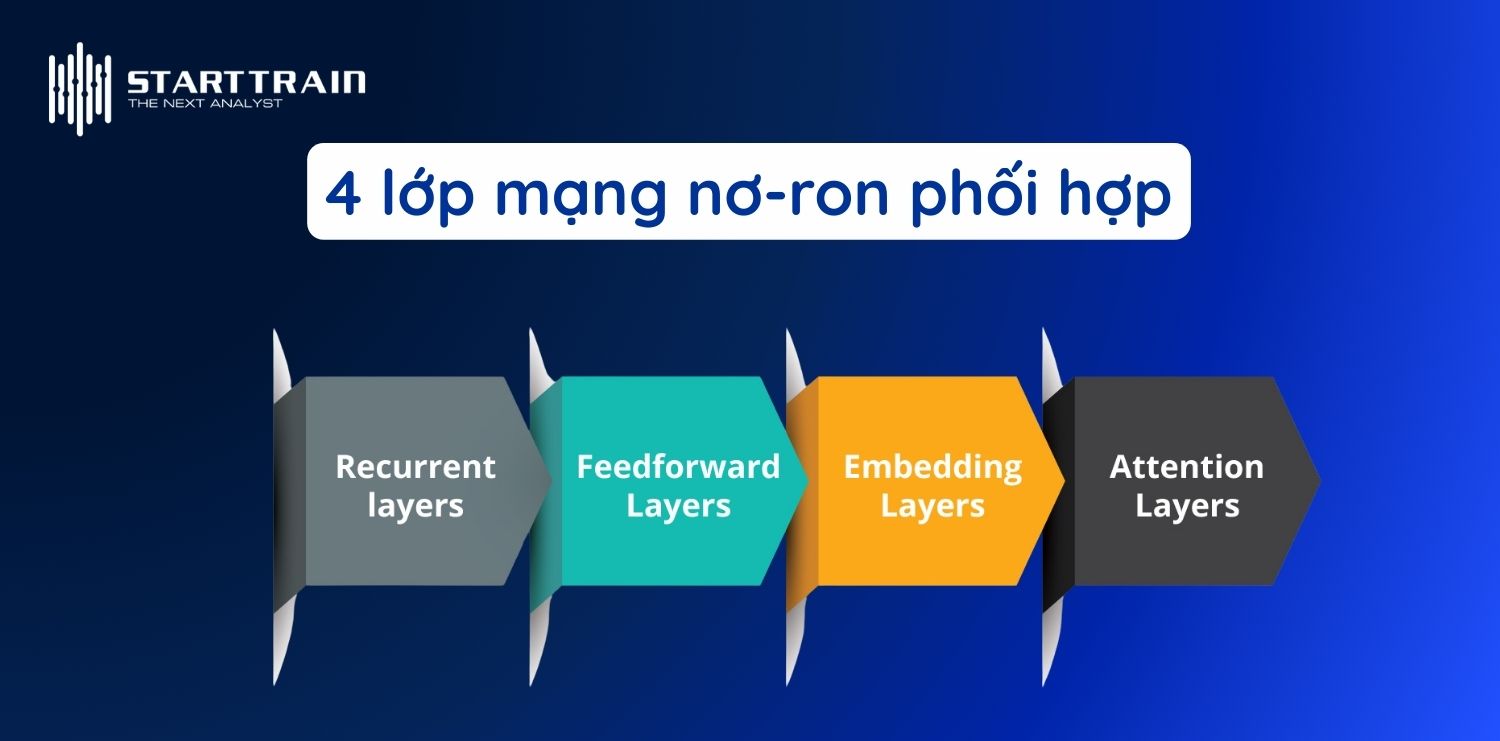
Sự xuất hiện của các mô hình ngôn ngữ lớn đã tạo ra một cuộc cách mạng thực sự trong cách chúng ta xử lý thông tin. Tầm quan trọng của LLM không chỉ nằm ở khả năng tạo văn bản mà còn ở tính linh hoạt và quy mô ứng dụng khổng lồ của chúng.
Một trong những lý do khiến LLM trở nên vô cùng quan trọng là khả năng thực hiện đồng thời nhiều tác vụ hoàn toàn khác nhau chỉ trên một mô hình duy nhất. Thay vì cần các mô hình chuyên biệt, một LLM có thể trả lời câu hỏi, tóm tắt tài liệu dài hàng trăm trang, dịch thuật đa ngôn ngữ và thậm chí là hoàn thành các đoạn mã lập trình. Khả năng này đang làm gián đoạn mạnh mẽ cách thức sáng tạo nội dung truyền thống, đồng thời định hình lại tương lai của các công cụ tìm kiếm và trợ lý ảo.

Dù không hoàn hảo, nhưng LLM đang thể hiện năng lực đáng kinh ngạc trong việc đưa ra các dự đoán chính xác dựa trên một lượng lời nhắc (prompt) hoặc dữ liệu đầu vào tương đối nhỏ. Đây chính là nền tảng của AI tạo sinh (Generative AI), cho phép con người tạo ra các sản phẩm trí tuệ phức tạp chỉ bằng ngôn ngữ tự nhiên. LLM giúp thu hẹp khoảng cách giữa ý tưởng và thực thi, biến các yêu cầu đơn giản thành các kết quả đầu ra có giá trị cao.
Tầm quan trọng của LLM còn thể hiện qua quy mô khổng lồ của chúng với hàng tỷ tham số, cho phép mô hình học được những mẫu dữ liệu cực kỳ phức tạp.
Nguyên lý hoạt động của mô hình ngôn ngữ lớn là sự kết hợp giữa toán học xác suất và kiến trúc mạng nơ-ron đa tầng. Thay vì hiểu ngôn ngữ như cách con người tư duy, LLM xử lý thông tin thông qua việc tính toán các con số và dự đoán xác suất.
LLM hoạt động dựa trên Deep Learning (Học sâu), mô phỏng cách não người xử lý thông tin thông qua các mạng nơ-ron nhiều lớp. Mỗi mạng này chứa hàng tỷ nút (node) được kết nối với nhau. Các kết nối này sở hữu hai thuộc tính then chốt là trọng số (weight) và độ lệch (bias). Cùng với các phần nhúng (embeddings), chúng tạo thành các tham số mô hình. Một mô hình càng lớn (nhiều tham số) thì khả năng thu thập và xử lý các mối liên hệ ngữ nghĩa phức tạp từ khối dữ liệu lớn càng mạnh mẽ.

Nguyên lý cốt lõi nhất của LLM là khả năng dự đoán token tiếp theo trong một chuỗi văn bản dựa trên ngữ cảnh của những từ đứng trước. Khi bạn đưa ra một câu lệnh, mô hình không đi tìm câu trả lời có sẵn trong bộ nhớ. Thay vào đó, nó tính toán xác suất để chọn ra token có khả năng xuất hiện cao nhất. Ví dụ, với câu “Cỏ có màu…”, dựa trên hàng tỷ mẫu dữ liệu đã học, mô hình sẽ gán xác suất cao nhất cho cụm “xanh lá” và sinh ra văn bản một cách tuần tự.
Transformer chính là bộ não cho phép LLM hiểu được ngữ cảnh sâu sắc. Khác với các mô hình cũ đọc văn bản theo thứ tự từ trái sang phải, Transformer xử lý toàn bộ đoạn văn song song. Đặc biệt, cơ chế Self-Attention giúp mô hình xác định đâu là thông tin quan trọng nhất trong câu. Nó đánh giá mối liên hệ giữa các từ bất kể khoảng cách địa lý của chúng trong văn bản. Điều này cho phép LLM nắm bắt được các cấu trúc ngữ pháp phức tạp và duy trì sự mạch lạc ngay cả trong các đoạn văn dài hàng trăm trang.
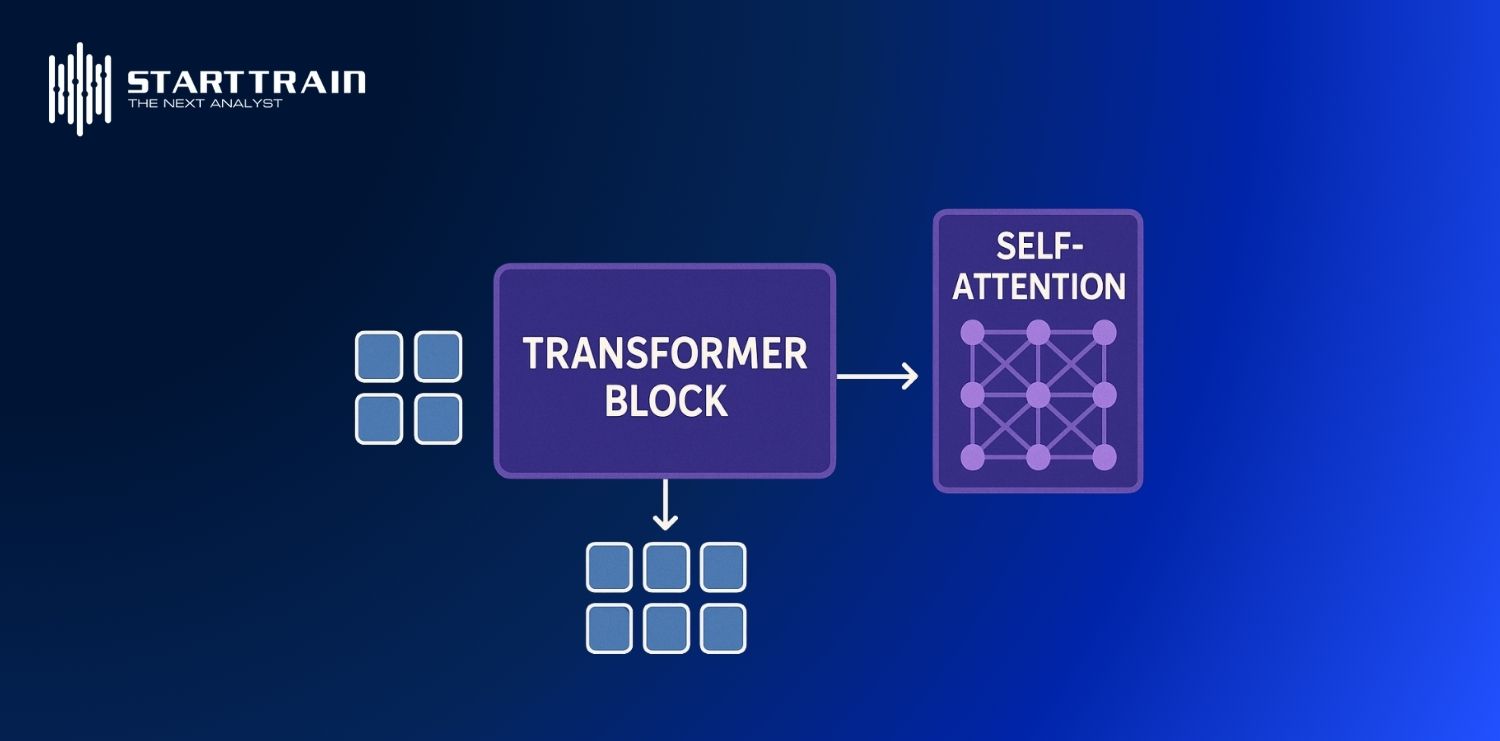
Trong giai đoạn đào tạo, LLM sử dụng các kỹ thuật tự học trên tập ngữ liệu khổng lồ. Mô hình sẽ liên tục so sánh dự đoán của mình với văn bản thực tế, sau đó tự điều chỉnh các giá trị tham số thông qua các thuật toán tối ưu hóa. Quá trình này lặp lại hàng tỷ lần cho đến khi mô hình có thể dự đoán chính xác các mã thông báo tiếp theo, từ đó hình thành nên khả năng hiểu quy luật ngôn ngữ và kiến thức thế giới một cách tự nhiên.
Sau khi hoàn tất đào tạo cơ bản, LLM có thể thích nghi với các tác vụ cụ thể thông qua ba phương thức chính:

Được xem là tiêu chuẩn vàng của làng LLM hiện nay. GPT-4 không chỉ mạnh về ngôn ngữ mà còn có khả năng đa phương thức (xử lý cả hình ảnh và văn bản). Đây là mô hình đứng sau phiên bản trả phí của ChatGPT, nổi tiếng với khả năng suy luận logic cực kỳ nhạy bén.
Câu trả lời mạnh mẽ từ Google. Gemini được thiết kế để trở thành mô hình đa phương thức ngay từ đầu, có khả năng tích hợp sâu vào hệ sinh thái của Google như tìm kiếm, tài liệu và email. Phiên bản Gemini Ultra hiện được đánh giá là đối thủ xứng tầm nhất của GPT-4.
Dòng mô hình Claude 3 (Haiku, Sonnet, Opus) đang gây sốt nhờ khả năng “đọc” ngữ cảnh cực dài và phong cách trả lời rất nhân văn, ít bị máy móc. Claude 3 được đánh giá cao về tính an toàn và khả năng tóm tắt các tài liệu kỹ thuật phức tạp.
Đây là mô hình ngôn ngữ lớn nguồn mở (open-source) hàng đầu hiện nay. Meta cung cấp Llama 3 cho cộng đồng phát triển miễn phí, tạo điều kiện cho các doanh nghiệp tự xây dựng AI riêng mà không phụ thuộc quá nhiều vào các dịch vụ trả phí.
Điểm khác biệt lớn nhất giữa mô hình ngôn ngữ lớn và mô hình ngôn ngữ truyền thống nằm ở khả năng ứng dụng kiến trúc học sâu trên một quy mô dữ liệu khổng lồ. Điều này giúp LLM tạo ra ngôn ngữ tự nhiên với độ chính xác cao và xử lý được các tác vụ cực kỳ phức tạp. Dưới đây là 8 điểm khác biệt cốt lõi:
Các mô hình truyền thống thường chỉ được huấn luyện trên các tập dữ liệu nhỏ và có giới hạn trong một phạm vi hẹp. Ngược lại, LLM sử dụng một khối lượng dữ liệu khổng lồ bao gồm hàng tỷ trang web, kho sách nhân loại, tài liệu nghiên cứu và mã nguồn lập trình, giúp nó sở hữu kho tri thức bao quát mọi lĩnh vực.
Mô hình ngôn ngữ truyền thống thường có khả năng hiểu ngữ cảnh rất kém, chủ yếu nhìn nhận các từ hoặc câu một cách riêng lẻ. Trong khi đó, LLM nhờ cơ chế Self-Attention có thể liên kết thông tin giữa nhiều câu, đoạn văn, thậm chí là toàn bộ một tài liệu dài để đưa ra câu trả lời nhất quán về mặt logic.

Trong khi các mô hình cũ thường chỉ làm tốt 1 – 2 nhiệm vụ cố định (ví dụ chỉ để phân loại thư rác), LLM là một siêu công cụ vô cùng đa năng. Nó có thể cùng lúc đảm nhận việc hỏi đáp, sáng tạo văn bản, dịch thuật, tóm tắt và cả lập trình mà không cần thay đổi cấu trúc nền tảng.
Phản hồi từ các mô hình truyền thống thường mang tính cứng nhắc, rập khuôn theo các mẫu có sẵn. LLM mang lại trải nghiệm hoàn toàn khác biệt với khả năng phản hồi tự nhiên, linh hoạt và có sắc thái giống hệt như con người đang trò chuyện.
Với các mô hình cũ, nếu muốn học thêm một khái niệm mới, bạn thường phải huấn luyện lại từ đầu. LLM có khả năng thích nghi cực nhanh thông qua các lời nhắc (prompt). Bạn có thể cung cấp ngữ cảnh mới ngay trong cuộc hội thoại và mô hình sẽ hiểu để áp dụng ngay lập tức.
Các mô hình truyền thống rất dễ bị bối rối trước những câu hỏi dài hoặc có nhiều tầng ý nghĩa. LLM được thiết kế để bóc tách và xử lý tốt các câu hỏi phức tạp, đòi hỏi sự suy luận logic và khả năng kết nối nhiều luồng thông tin khác nhau.

Mô hình ngôn ngữ truyền thống chủ yếu xuất hiện trong các hệ thống đơn giản như bộ lọc từ khóa. LLM hiện nay đang thống trị các ứng dụng cao cấp như chatbot thông minh, trợ lý ảo cá nhân hóa, hệ thống phân tích nội dung tự động và hỗ trợ nghiên cứu khoa học.
Người dùng khi tương tác với mô hình truyền thống dễ dàng nhận thấy cảm giác máy móc và giới hạn. LLM nâng tầm trải nghiệm với sự tương tác mượt mà, thấu hiểu ý định người dùng sâu sắc, tạo ra cảm giác gần gũi và hiệu quả hơn nhiều lần.

Tóm lại, LLM (Mô hình Ngôn ngữ Lớn) không chỉ là một công cụ công nghệ mà còn là một bước ngoặt vĩ đại trong lịch sử phát triển trí tuệ nhân tạo. Với khả năng hiểu và sinh ngôn ngữ tự nhiên ở trình độ cao, LLM đang mở ra những cánh cửa mới cho sự sáng tạo và hiệu suất làm việc của con người.
Hiểu rõ LLM là gì giúp chúng ta nhận thấy tiềm năng vô hạn của trí tuệ nhân tạo. Tuy vẫn còn những hạn chế về độ chính xác và chi phí vận hành, nhưng tốc độ cải tiến nhanh chóng của các kiến trúc như Transformer hứa hẹn sẽ mang đến những phiên bản AI thông minh và an toàn hơn trong tương lai gần. Việc nắm bắt và ứng dụng LLM ngay từ bây giờ sẽ là lợi thế cạnh tranh không thể bỏ qua cho cả cá nhân và doanh nghiệp trong kỷ nguyên số.
Nếu bạn muốn nâng cao nền tảng tư duy, công cụ phân tích và ứng dụng chúng vào quy trình vận hành thực tế, hãy tham khảo các lộ trình đào tạo tại Starttrain: Khóa học Business Intelligence Essentials