Địa chỉ:
Lầu 7 Tòa nhà STA, 618 đường 3/2, Phường Diên Hồng (Phường 14, Quận 10), TP HCM
Giờ làm việc
Thứ 2 tới thứ 6: 8:00 - 17:00
Địa chỉ:
Lầu 7 Tòa nhà STA, 618 đường 3/2, Phường Diên Hồng (Phường 14, Quận 10), TP HCM
Giờ làm việc
Thứ 2 tới thứ 6: 8:00 - 17:00
Chuẩn hóa dữ liệu (Data Normalization) là một trong những khái niệm nền tảng và quan trọng nhất trong thiết kế cơ sở dữ liệu (CSDL) quan hệ. Nó không chỉ là một quy trình kỹ thuật mà còn là một triết lý giúp kiến trúc sư dữ liệu xây dựng các hệ thống mạnh mẽ, hiệu quả và dễ bảo trì. Nếu bạn đang tìm cách loại bỏ sự dư thừa, tối ưu hóa không gian lưu trữ, và đảm bảo tính toàn vẹn dữ liệu, thì chuẩn hóa chính là chìa khóa.
Chuẩn hóa dữ liệu (Data Normalization) là một kỹ thuật được sử dụng trong cơ sở dữ liệu quan hệ để tổ chức dữ liệu một cách hiệu quả. Nó nhằm mục đích giảm thiểu sự dư thừa (Redundancy) và nâng cao tính toàn vẹn dữ liệu (Data Integrity) bằng cách chia bảng lớn thành các bảng nhỏ hơn, chuyên biệt hơn và liên kết chúng thông qua các khóa.
Nếu không có chuẩn hóa, cơ sở dữ liệu sẽ phải đối mặt với các vấn đề bất thường (Anomalies) nghiêm trọng khi thao tác dữ liệu, bao gồm:
Quá trình này được thực hiện qua một loạt các bước gọi là dạng chuẩn (Normal Forms), trong đó mỗi dạng chuẩn đều dựa trên dạng chuẩn trước đó để áp đặt các quy tắc nghiêm ngặt hơn.
Xem thêm: Big Data là gì? Tầm quan trọng và ứng dụng của dữ liệu lớn
Về bản chất, chuẩn hóa dữ liệu (Data Normalization) là nền tảng giúp các doanh nghiệp và tổ chức quản lý, truy vấn và bảo trì khối lượng dữ liệu khổng lồ, phức tạp và có tính liên kết chặt chẽ một cách hiệu quả tối đa.
Nhu cầu này đã có từ lâu. Ngay từ những năm 1970, Edgar F. Codd, nhà toán học tại IBM và cha đẻ của mô hình dữ liệu quan hệ, đã đề xuất chuẩn hóa như một giải pháp thiết yếu để loại bỏ các “phụ thuộc không mong muốn” (undesirable dependencies) giữa các thuộc tính, từ đó khắc phục các sự cố tiềm ẩn.
Trong một cấu trúc cơ sở dữ liệu phức tạp với các bản ghi liên kết, việc thay đổi một giá trị đơn lẻ trong một bảng lớn có thể gây ra những hệ quả không lường trước được, dẫn đến mất mát hoặc không nhất quán dữ liệu. Chuẩn hóa được thiết kế chính để phòng ngừa những rủi ro này.

Việc áp dụng chuẩn hóa dữ liệu mang lại nhiều lợi ích thiết thực, giúp dữ liệu của bạn luôn sạch sẽ, nhất quán và loại bỏ lỗi:

Quá trình chuẩn hóa dữ liệu thường diễn ra theo các giai đoạn, mỗi giai đoạn tương ứng với một dạng chuẩn (Normal Form) cụ thể. Khi tiến lên các giai đoạn cao hơn, dữ liệu sẽ được tổ chức ngăn nắp hơn, giảm thiểu sự dư thừa và tăng cường tính nhất quán.

Trong giai đoạn 1NF, quy tắc cơ bản là mỗi cột trong bảng phải là duy nhất và không được có sự lặp lại của các nhóm dữ liệu. Mỗi bản ghi phải có một định danh duy nhất, được gọi là khóa chính (Primary Key). Yêu cầu quan trọng nhất là giá trị nguyên tố (Atomic Value): mỗi ô (trường/cell) trong bảng chỉ được phép chứa một giá trị duy nhất. Để đạt được 1NF, nếu một cột chứa nhiều mặt hàng, bạn phải tách mỗi mặt hàng thành một hàng riêng biệt.
Xây dựng trên nền tảng 1NF, ở giai đoạn này, tất cả các thuộc tính không phải khóa phải phụ thuộc hoàn toàn vào toàn bộ khóa chính (Primary Key). Nói cách khác, các cột không phải là khóa trong bảng phải phụ thuộc hoàn toàn vào mọi khóa ứng viên. Điều kiện này đặc biệt quan trọng khi khóa chính là khóa tổng hợp (Composite Key), tức là khóa gồm nhiều cột. Ví dụ, nếu khóa chính là (Mã_Đơn_hàng, Mã_Sản_phẩm), ta phải tách các thuộc tính chỉ phụ thuộc vào Mã_Sản_phẩm sang bảng riêng để đạt 2NF.
Để đạt 3NF, bảng phải ở 2NF và loại bỏ hoàn toàn các phụ thuộc bắc cầu (Transitive Dependency). Phụ thuộc bắc cầu xảy ra khi một thuộc tính không phải khóa lại phụ thuộc vào một thuộc tính không phải khóa khác, thay vì phụ thuộc trực tiếp vào khóa chính. Mục tiêu của 3NF là đảm bảo mọi cột không phải khóa đều phụ thuộc một cách phi bắc cầu (non-transitively) vào mỗi khóa trong bảng. Ví dụ: Trong bảng Nhân_viên, nếu Mã_NV -> Mã_Phòng_Ban và Mã_Phòng_Ban -> Tên_Phòng_Ban, ta phải tách Mã_Phòng_Ban và Tên_Phòng_Ban sang bảng phòng ban riêng.
BCNF, còn được coi là mức độ cao hơn của 3NF, là dạng chuẩn đảm bảo tính hợp lệ cao hơn cho các phụ thuộc dữ liệu. Để đạt BCNF, mọi yếu tố quyết định (determinant) phải là một khóa ứng viên (Candidate Key). Điều này có nghĩa là mọi phụ thuộc của bất kỳ thuộc tính nào vào các thuộc tính không phải khóa đều bị loại bỏ. BCNF đảm bảo rằng không có thuộc tính phụ thuộc nào không có một thuộc tính độc lập làm khóa ứng viên của nó.
4NF đưa việc giảm thiểu sự dư thừa dữ liệu lên một cấp độ mới bằng cách xử lý các sự kiện đa giá trị (multi-valued facts). Nói một cách đơn giản, một bảng nằm ở dạng chuẩn 4NF khi nó không gây ra bất kỳ bất thường cập nhật nào và khi một bảng chứa nhiều thuộc tính, mỗi thuộc tính đó đều độc lập với nhau. 4NF loại bỏ tận gốc sự dư thừa dữ liệu liên quan đến các phụ thuộc đa trị, đảm bảo rằng một bảng không chứa hai hoặc nhiều sự kiện đa trị độc lập về nhau.
Cần phân biệt rõ ràng giữa chuẩn hóa trong thiết kế cơ sở dữ liệu (Normalization) và chuẩn hóa/điều chỉnh tỷ lệ trong khoa học dữ liệu (Scaling/Normalization).
Trong các quy trình phân tích dữ liệu và học máy (Machine Learning), chuẩn hóa dữ liệu là một bước tiền xử lý thiết yếu. Mục tiêu của nó là điều chỉnh tỷ lệ của dữ liệu, đảm bảo rằng tất cả các biến số trong tập dữ liệu đều nằm trên một phạm vi giá trị tương tự. Sự đồng nhất này rất quan trọng vì nó ngăn chặn bất kỳ biến số nào có thang đo lớn áp đảo hoặc làm lu mờ những biến số khác trong quá trình tính toán.
Đối với các thuật toán học máy dựa trên khoảng cách (distance-based) hoặc dựa trên gradient (gradient-based), dữ liệu được chuẩn hóa là chìa khóa. Nó giúp các thuật toán này hoạt động tối ưu, dẫn đến việc tạo ra các mô hình chính xác, đáng tin cậy và không thiên vị. Điều này nâng cao chất lượng insights thu được từ dữ liệu.

Khoa học dữ liệu và học máy sử dụng nhiều kỹ thuật để chuẩn hóa dữ liệu. Dưới đây là ba phương pháp được áp dụng phổ biến nhất.
Kỹ thuật này thực hiện phép biến đổi tuyến tính trên dữ liệu gốc. Mỗi giá trị được thay thế theo một công thức có tính đến giá trị tối thiểu (Xmin) và tối đa (Xmax) của dữ liệu. Mục tiêu là điều chỉnh tỷ lệ dữ liệu về một phạm vi cụ thể, thường là [0, 1].
Công thức cho chuẩn hóa Min-Max:
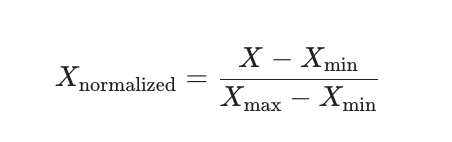
Còn được gọi là chuẩn hóa về trung bình bằng 0 (Zero mean normalization) hoặc tiêu chuẩn hóa (standardization), kỹ thuật này chuẩn hóa các giá trị dựa trên giá trị trung bình (μ) và độ lệch chuẩn (σ) của dữ liệu. Mỗi giá trị được thay thế bằng một điểm Z-score, cho biết giá trị đó cách giá trị trung bình bao nhiêu lần độ lệch chuẩn.
Công thức cho chuẩn hóa Z-Score:
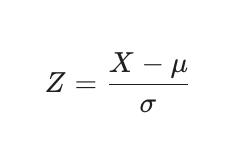
Kỹ thuật đơn giản này chuẩn hóa dữ liệu bằng cách di chuyển dấu thập phân của các giá trị. Mỗi giá trị của dữ liệu được chia cho giá trị tuyệt đối tối đa của dữ liệu, kết quả là các giá trị thường nằm trong phạm vi từ -1 đến 1.
Công thức cho chuẩn hóa tỷ lệ thập phân:
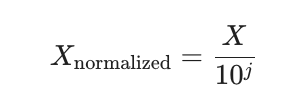
Trong đó, j là số nguyên nhỏ nhất sao cho giá trị tuyệt đối tối đa của tất cả các giá trị sau khi chia đều nhỏ hơn 1.
Chuẩn hóa dữ liệu (Data Normalization) là một quy trình không thể thiếu, là nền tảng vững chắc cho mọi hệ thống quản lý và phân tích dữ liệu hiện đại. Dù bạn đang thiết kế một CSDL quan hệ từ 1NF đến BCNF để loại bỏ sự dư thừa và bất thường dữ liệu, hay đang áp dụng các kỹ thuật như Min-Max Scaling trong các quy trình Học máy để tối ưu hóa hiệu suất thuật toán, nguyên tắc cốt lõi vẫn là tạo ra sự nhất quán và hiệu quả.
Việc đầu tư vào chuẩn hóa không chỉ giúp tiết kiệm chi phí lưu trữ và tăng tốc độ truy vấn, mà còn đảm bảo tính toàn vẹn và khả năng mở rộng lâu dài của toàn bộ kiến trúc dữ liệu của bạn. Hãy xem chuẩn hóa là bước đầu tiên để biến dữ liệu thô thành tài sản có giá trị và đáng tin cậy.
Tham khảo thêm:
- Làm chủ ngôn ngữ truy vấn SQL chỉ sau 4 buổi học
- Khóa học Business Intelligence Essentials







