Địa chỉ:
Lầu 7 Tòa nhà STA, 618 đường 3/2, Phường Diên Hồng (Phường 14, Quận 10), TP HCM
Giờ làm việc
Thứ 2 tới thứ 6: 8:00 - 17:00
Địa chỉ:
Lầu 7 Tòa nhà STA, 618 đường 3/2, Phường Diên Hồng (Phường 14, Quận 10), TP HCM
Giờ làm việc
Thứ 2 tới thứ 6: 8:00 - 17:00
Trong kỷ nguyên bùng nổ của ChatGPT, Claude hay Gemini, chúng ta thường nghe nhắc đến khái niệm “giới hạn token” hoặc “chi phí tính theo token”. Vậy thực chất token là gì và tại sao nó lại đóng vai trò sống còn trong việc vận hành các hệ thống AI hiện nay? Hãy cùng Starttrain tìm hiểu chi tiết qua bài viết dưới đây.
Để hiểu token là gì một cách đơn giản nhất, hãy coi các mô hình AI ngôn ngữ là một tòa nhà đồ sộ, và token chính là những viên gạch nhỏ nhất để xây dựng nên tòa nhà đó. Trong lĩnh vực AI, token đóng vai trò là đơn vị dữ liệu cơ bản mà các mô hình trí tuệ nhân tạo sử dụng để tiếp nhận, xử lý và tạo ra thông tin.
Token là thành phần cốt lõi cấu thành nên cả quá trình đào tạo (training) và suy luận (inference) của các hệ thống AI. Tương tự như cách từ ngữ tạo thành nền tảng cho sự hiểu biết và giao tiếp của con người, token là cách các mô hình máy học tiêu hóa dữ liệu.
Hiệu quả của một mô hình AI phụ thuộc rất lớn vào việc quá trình token hóa có nắm bắt được bản chất của dữ liệu đầu vào hay không. Nếu các token được định nghĩa kém hoặc không phù hợp (quá chi tiết hoặc quá tổng quát), mô hình có thể bỏ lỡ các mối quan hệ logic hoặc những mẫu quan trọng, từ đó cản trở khả năng học hỏi và hiệu suất tổng thể.

Token là gì trong giao tiếp? Token không chỉ là đơn vị xử lý nội bộ mà còn là ngôn ngữ chung để con người tương tác với AI. Khi bạn nhập một câu lệnh (prompt), hệ thống sẽ chuyển đổi văn bản đó thành một chuỗi các token để mô hình hiểu được. Ngược lại, khi AI phản hồi, nó tạo ra một chuỗi token và dịch ngược lại thành định dạng văn bản hoặc hình ảnh mà chúng ta có thể đọc được.
Đặc biệt, tốc độ xử lý token tỉ lệ thuận với hiệu suất của ứng dụng: token được xử lý càng nhanh, AI càng học hỏi và phản hồi nhanh chóng, điều này cực kỳ quan trọng đối với các ứng dụng thực tế đòi hỏi tính thời gian thực.
Hiện nay, một loại hình trung tâm dữ liệu mới gọi là AI Factory đang trỗi dậy để tối ưu hóa việc xử lý token. Tại đây, các thuật toán biến token từ “ngôn ngữ của AI” thành “đơn vị tiền tệ của AI” – chính là sự thông minh (intelligence). Với các giải pháp điện toán toàn diện và GPU thế hệ mới (như NVIDIA), doanh nghiệp có thể xử lý lượng token khổng lồ với chi phí thấp hơn đáng kể.
Việc tối ưu hóa phần mềm và phần cứng đã giúp giảm chi phí cho mỗi token xuống gấp nhiều lần so với trước đây, tạo ra giá trị gia tăng vượt trội và doanh thu nhanh chóng cho các doanh nghiệp ứng dụng AI.

Quy trình xử lý token (Tokenization) không đơn thuần là việc cắt nhỏ văn bản, mà là một quy trình kỹ thuật phức tạp giúp máy tính hiểu được ngữ nghĩa ẩn sau dữ liệu.
Khi nhận dữ liệu đầu vào (văn bản, hình ảnh hoặc âm thanh), AI sẽ thực hiện bước chia nhỏ chúng thành các đơn vị tối thiểu. Với văn bản, một từ dài như “darkness” có thể được tách thành “dark” và “ness”. Việc chia nhỏ này giúp AI nhận diện được các gốc từ chung giữa những từ khác nhau, từ đó nắm bắt được các mẫu ngữ pháp và ngữ nghĩa lặp lại trong ngôn ngữ.
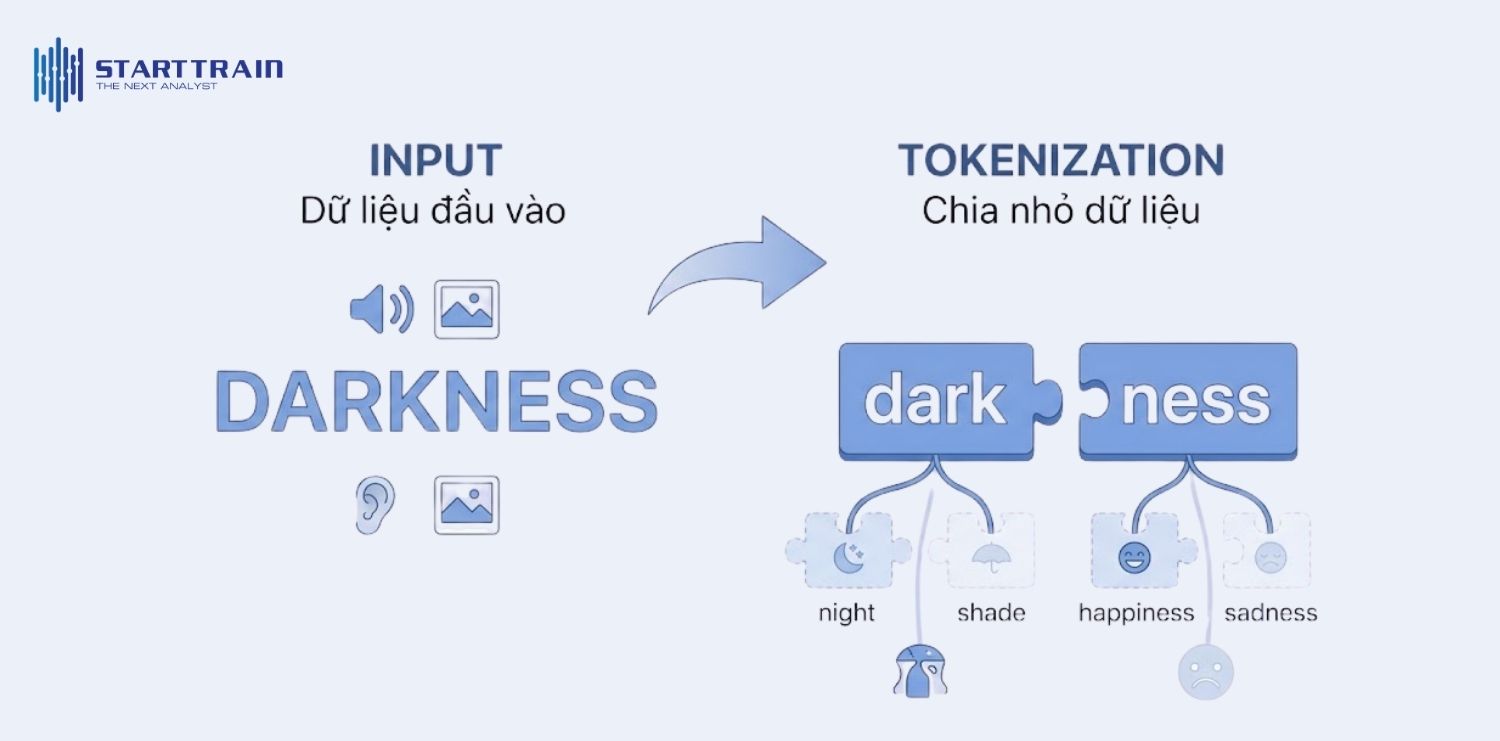
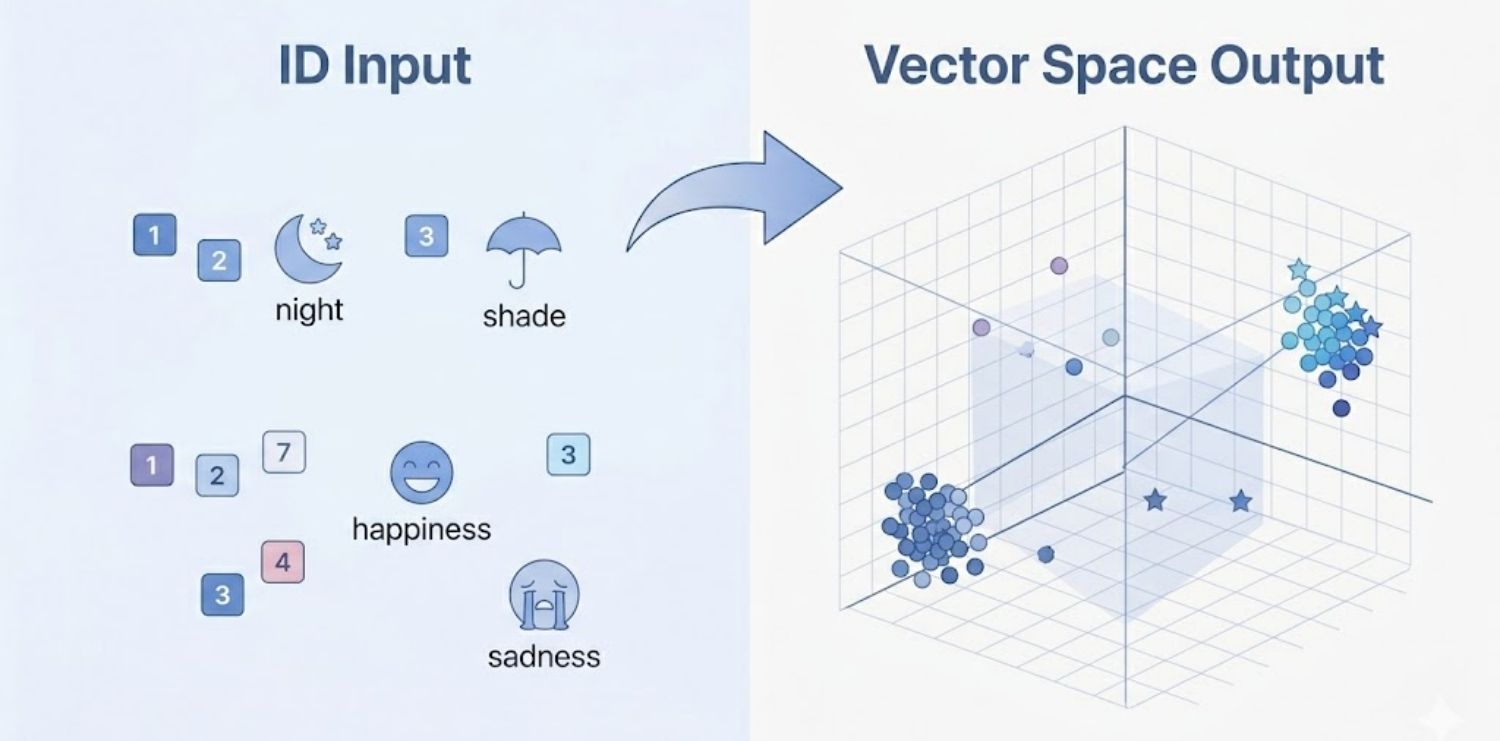
Sau khi đã được chia nhỏ, mỗi token sẽ được gán cho một mã số ID duy nhất dựa trên bộ từ điển (vocabulary) của mô hình. Ví dụ, token “dark” có thể mang mã 217, còn “ness” là 655. Tuy nhiên, một bộ mã hóa thông minh sẽ không gán mã một cách máy móc. Tùy thuộc vào ngữ cảnh, cùng một từ “lie” (nằm nghỉ) và “lie” (nói dối) có thể được gán các mã định danh khác nhau để AI phân biệt được ý định của người dùng ngay từ bước nạp dữ liệu.
Các mã số ID sau đó được chuyển thành các vector – những dãy số nhiều chiều trong không gian toán học. Đây là giai đoạn then chốt nơi AI xác định khoảng cách ngữ nghĩa. Các token có ý nghĩa gần nhau sẽ nằm gần nhau trong không gian vector này. Điều này cho phép AI xử lý các khái niệm trừu tượng và hiểu được mối quan hệ phức tạp giữa các thành phần trong câu.
Dựa trên chuỗi các vector đầu vào, mô hình AI sẽ thực hiện các phép toán xác suất để dự đoán token tiếp theo có khả năng xuất hiện cao nhất. Quy trình này lặp đi lặp lại hàng nghìn lần trong tích tắc để tạo ra một câu trả lời hoàn chỉnh. Càng có nhiều token chất lượng trong quá trình đào tạo, AI càng có khả năng dự đoán chính xác và đưa ra phản hồi tự nhiên, logic như con người.
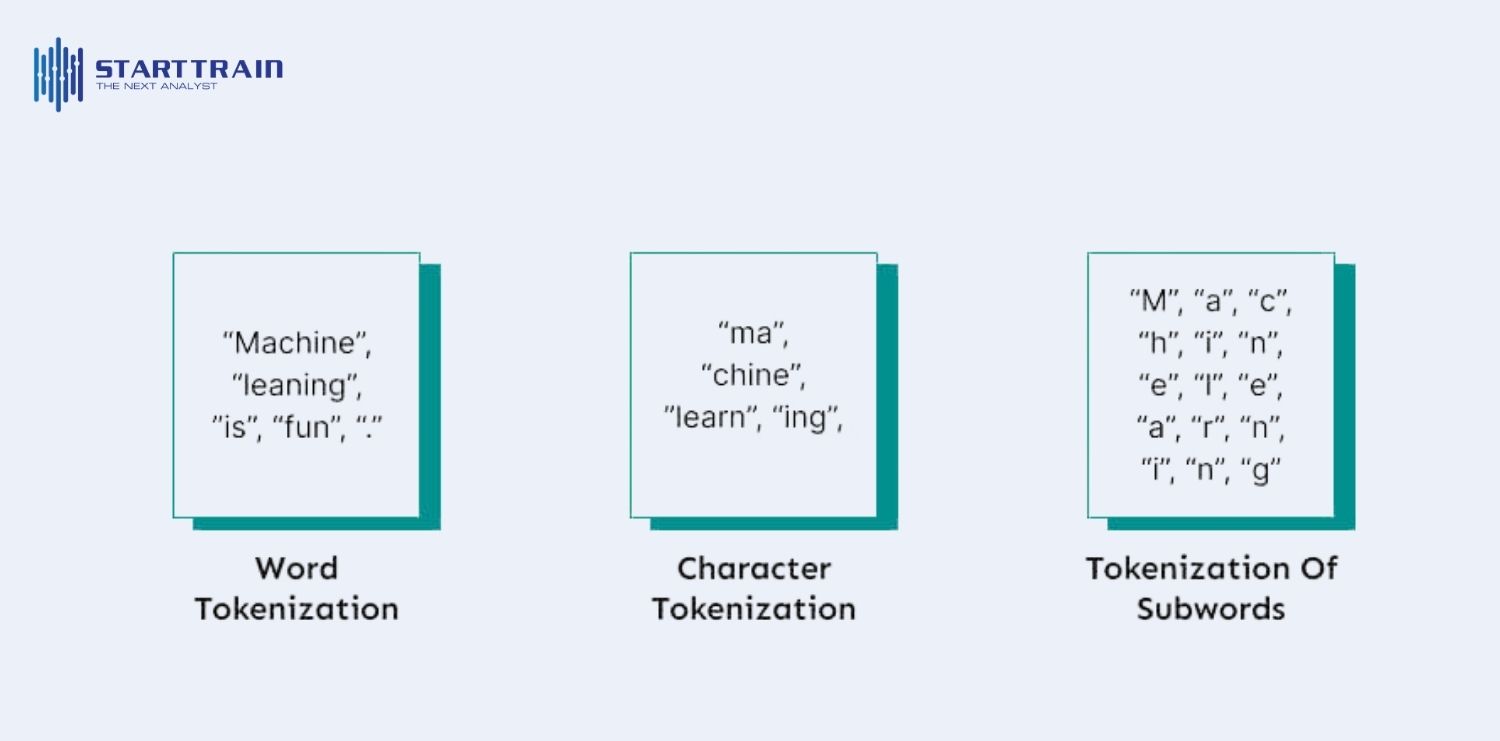
Tùy thuộc vào loại dữ liệu và yêu cầu về độ chính xác, các mô hình AI sẽ áp dụng những phương pháp token hóa văn bản khác nhau.
Phương pháp này phân tách văn bản thành từng ký tự riêng lẻ (a, b, c, d…). Nó cực kỳ linh hoạt vì có thể xử lý mọi từ mới phát sinh. Tuy nhiên, chuỗi token sẽ trở nên rất dài, khiến mô hình tốn nhiều tài nguyên tính toán và khó học được các mối quan hệ ngữ nghĩa lâu dài (ví dụ từ “sinh viên” bị xé nhỏ quá mức sẽ mất đi ý nghĩa của cả cụm).
Đây là tiêu chuẩn cho các LLM hiện đại như GPT, BERT hay T5. Nó chia từ thành các phần nhỏ hơn như tiền tố và hậu tố (ví dụ: “unhappy” -> [“un”, “happy”]). Kỹ thuật này (như Byte-Pair Encoding – BPE) giúp cân bằng hoàn hảo giữa kích thước từ vựng và khả năng hiểu cả từ phổ biến lẫn từ hiếm, giúp AI không bị lúng túng khi gặp các biến thể từ ngữ.
Trong quá trình xử lý, AI còn sử dụng các “Special Token” để điều hướng cấu trúc. Ví dụ, token đánh dấu bắt đầu câu, kết thúc câu hoặc các vị trí quan trọng ngoài từ vựng. Những token này giúp AI duy trì được cấu trúc văn bản và không bị nhầm lẫn giữa các đoạn hội thoại khác nhau. Một số token đặc biệt như <|endoftext|> thường không bị tính phí trong một số hệ thống, trong khi các ký tự như xuống dòng \n vẫn được tính như token thông thường.
Mọi loại dữ liệu khi đưa vào Transformer AI hiện đại đều phải được “token hóa” để chuyển đổi sang ngôn ngữ máy:
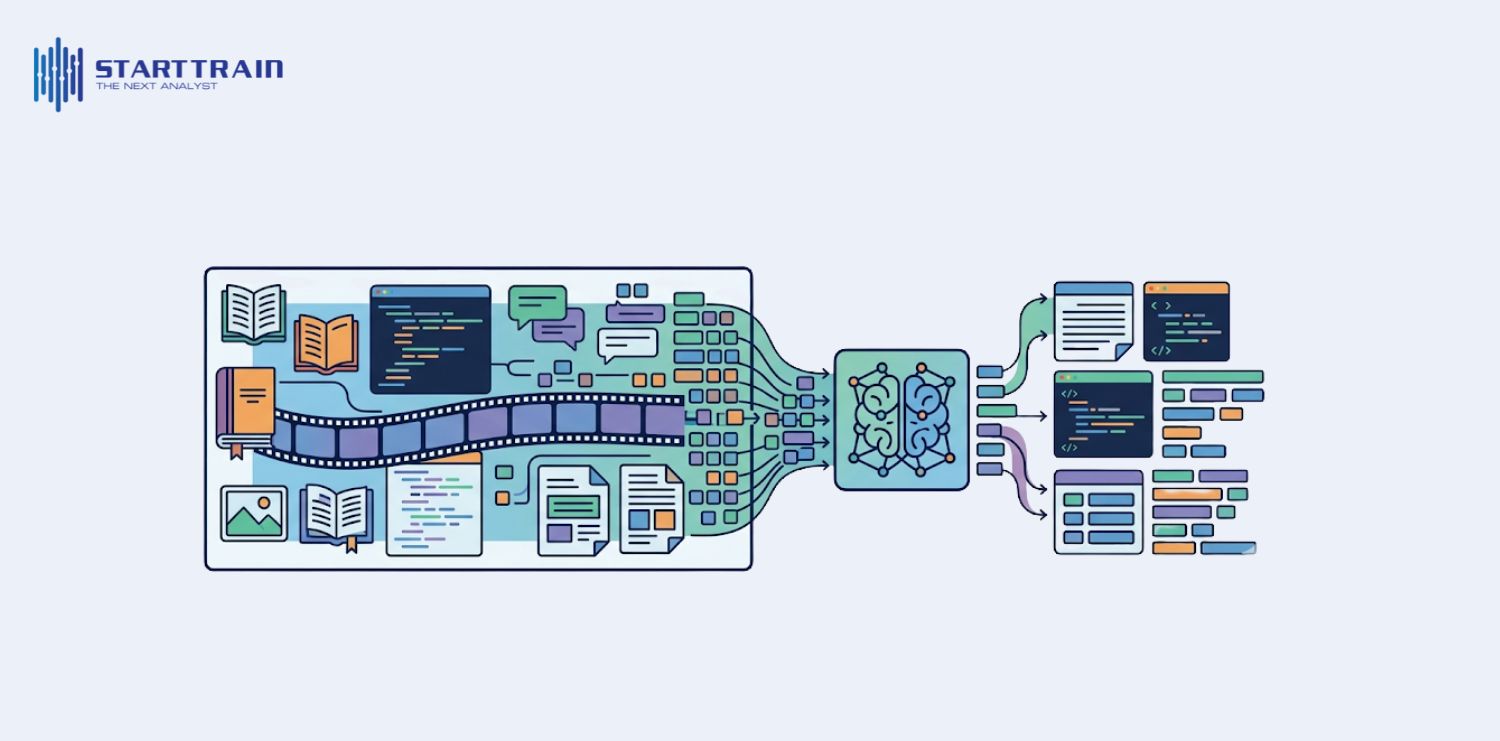
Đây là giai đoạn chuyển mình mạnh mẽ nhất của các mô hình AI hiện đại, nơi token không chỉ đại diện cho đầu ra mà còn là quá trình suy nghĩ bên trong của máy móc.
Trong giai đoạn suy luận, AI tiếp nhận một “prompt” (văn bản, hình ảnh hoặc mã lệnh), dịch chúng thành chuỗi token và dự đoán các token phản hồi. Khả năng hiểu trọn vẹn yêu cầu của người dùng phụ thuộc vào Context Window (Cửa sổ ngữ cảnh).
Khác với các AI truyền thống thường đưa ra phản hồi ngay lập tức (next-token prediction), các mô hình “tư duy” thế hệ mới (như dòng OpenAI o1) giới thiệu khái niệm Reasoning Tokens.

Hiểu rõ token là gì sẽ giúp bạn sử dụng AI hiệu quả hơn.
Các prompt ngắn không chỉ giúp tiết kiệm số lượng token đầu vào mà còn giúp AI tập trung hơn vào yêu cầu chính, từ đó đưa ra câu trả lời chất lượng hơn. Hãy cân nhắc kỹ lượng ngữ cảnh vừa đủ để đạt được kết quả mong muốn mà không gây lãng phí.
Cấu trúc ngữ pháp của các ngôn ngữ khác nhau ảnh hưởng lớn đến cách tính token. Tiếng Anh thường tối ưu nhất về số lượng token, trong khi các ngôn ngữ khác như tiếng Việt, tiếng Đức hay tiếng Ba Lan có thể tốn nhiều token hơn đáng kể cho cùng một nội dung. Chọn ngôn ngữ phù hợp với mục tiêu chi phí và mục đích sử dụng là một chiến lược thông minh.
Để tránh việc hết giới hạn token khi trò chuyện dài, bạn có thể áp dụng các mẹo sau:

Mỗi mô hình (như GPT-3.5, GPT-4 hay GPT-4o) có mức giá và chất lượng khác nhau. Nếu nhiệm vụ của bạn đơn giản, các phiên bản cũ hoặc nhỏ hơn có thể giúp tiết kiệm chi phí mà vẫn đảm bảo hiệu quả công việc.
Thông thường, đối với tiếng Anh, 1.000 token tương đương khoảng 750 từ. Đối với tiếng Việt, do có dấu và cấu trúc phức tạp, 1 từ có thể tốn từ 1.5 đến 3 token.
Vì token phản ánh chính xác sức mạnh tính toán (compute) mà máy chủ phải bỏ ra để xử lý yêu cầu của bạn.
Bạn có thể sử dụng công cụ Tokenizer của OpenAI hoặc thư viện Tiktoken trong Python để đếm chính xác số lượng token mà văn bản tiêu thụ.
Hiểu rõ token là gì không chỉ đơn thuần là nắm vững một thuật ngữ kỹ thuật, mà còn là chìa khóa để làm chủ hiệu suất và chi phí trong kỷ nguyên trí tuệ nhân tạo. Từ những viên gạch dữ liệu thô sơ, qua quá trình token hóa tinh vi, AI đã có thể học hỏi, suy luận và thậm chí là tư duy để giải quyết các vấn đề phức tạp của con người.
Khi các mô hình ngôn ngữ lớn (LLM) tiếp tục tiến hóa với các khái niệm mới như Reasoning Tokens hay cửa sổ ngữ cảnh khổng lồ, việc quản lý token hiệu quả sẽ trở thành một kỹ năng thiết yếu. Hy vọng qua bài viết này, bạn đã trang bị được cho mình những kiến thức cần thiết để tối ưu hóa trải nghiệm và khai thác tối đa sức mạnh từ các hệ thống AI hiện đại.







