Địa chỉ:
Lầu 7 Tòa nhà STA, 618 đường 3/2, Phường Diên Hồng (Phường 14, Quận 10), TP HCM
Giờ làm việc
Thứ 2 tới thứ 6: 8:00 - 17:00
Địa chỉ:
Lầu 7 Tòa nhà STA, 618 đường 3/2, Phường Diên Hồng (Phường 14, Quận 10), TP HCM
Giờ làm việc
Thứ 2 tới thứ 6: 8:00 - 17:00
Trong bối cảnh chuyển đổi số hiện nay, dữ liệu đóng vai trò là nguồn tài nguyên cốt lõi của mọi tổ chức. Tuy nhiên, việc thu thập dữ liệu thô sẽ không mang lại giá trị thực tiễn nếu thiếu đi các phương pháp khai thác khoa học. Predictive Analytics ra đời như một giải pháp then chốt, giúp doanh nghiệp phân tích các mẫu dữ liệu trong quá khứ để xác định khả năng xảy ra của các sự kiện tương lai, từ đó tối ưu hóa quá trình ra quyết định chiến lược.
Predictive Analytics (Phân tích dự đoán) là một nhánh của phân tích nâng cao (advanced analytics), sử dụng dữ liệu lịch sử kết hợp với các mô hình thống kê, kỹ thuật khai thác dữ liệu (data mining) và học máy (Machine Learning) để đưa ra các dự báo về kết quả trong tương lai.
Các doanh nghiệp áp dụng phân tích dự đoán để tìm ra các mẫu hình (patterns) ẩn trong dữ liệu, từ đó nhận diện các rủi ro tiềm ẩn cũng như những cơ hội mới. Lĩnh vực này thường gắn liền chặt chẽ với dữ liệu lớn và khoa học dữ liệu.

Ngày nay, các tổ chức đang đối mặt với sự bùng nổ của dữ liệu, từ các tệp nhật ký hệ thống (log files) cho đến hình ảnh và video. Những dữ liệu này thường nằm rải rác trong nhiều kho lưu trữ khác nhau. Để khai thác giá trị từ chúng, các chuyên gia dữ liệu sử dụng thuật toán Deep Learning và Machine Learning để phát hiện các quy luật và dự đoán các sự kiện sắp tới.
Một đặc điểm quan trọng của các kỹ thuật này là khả năng học hỏi liên tục. Kết quả dự báo ban đầu có thể được sử dụng làm đầu vào để tinh chỉnh và đưa ra những insights chính xác hơn nữa.
Phân tích dự đoán không chỉ đơn thuần là việc kéo dài các đường xu hướng từ quá khứ vào tương lai. Nó là một quá trình phức tạp kết hợp giữa khoa học dữ liệu và tư duy kinh doanh.
Về cốt lõi, phân tích dự đoán hoạt động dựa trên giả định rằng các mẫu hành vi trong quá khứ có xác suất lặp lại cao trong tương lai. Các thuật toán sẽ quét qua hàng triệu điểm dữ liệu lịch sử để tìm kiếm những bằng chứng hoặc quy luật lặp đi lặp lại.
Ví dụ, trong ngành bán lẻ, hệ thống có thể nhận thấy rằng doanh số của một loại đồ uống cụ thể luôn tăng vọt khi nhiệt độ ngoài trời vượt quá 30 độ C và có sự kiện thể thao lớn diễn ra. Bằng cách xác định các mối liên kết này, mô hình có thể đo lường chính xác xác suất các mẫu hình đó sẽ tái diễn khi các điều kiện tương tự xuất hiện.
Để đưa ra những dự báo có độ chính xác cao, Predictive Analytics dựa trên một hệ sinh thái các kỹ thuật bổ trợ lẫn nhau:

Các mô hình dự đoán thường không bắt đầu từ con số không mà được xây dựng trên nền tảng của các mô hình thống kê mô tả (descriptive models). Nếu mô hình mô tả giúp doanh nghiệp hiểu rõ “điều gì đã xảy ra” và “tại sao nó lại xảy ra” bằng cách xác định các mối quan hệ và cấu trúc trong dữ liệu cũ, thì mô hình dự đoán sẽ tiến thêm một bước quan trọng.
Nó đánh giá xem nếu một mắt xích trong quy trình thay đổi (ví dụ: thay đổi giá bán hoặc sự thay đổi trong hành vi người tiêu dùng), thì kết quả cuối cùng sẽ biến động như thế nào trong tương lai.
Quá trình biến dữ liệu thô thành thông tin dự báo thường tuân theo một vòng đời khép kín:
Các mô hình phân tích dự đoán được thiết kế để đánh giá dữ liệu lịch sử, phát hiện xu hướng và sử dụng thông tin đó để dự báo các biến động trong tương lai. Có ba loại mô hình phổ biến nhất hiện nay:
Thuộc nhánh học máy có giám sát (supervised machine learning), mô hình này phân loại dữ liệu vào các nhóm dựa trên các mối quan hệ đã biết từ dữ liệu lịch sử. Nó thường được sử dụng để trả lời các câu hỏi nhị phân (Có/Không, Đúng/Sai).
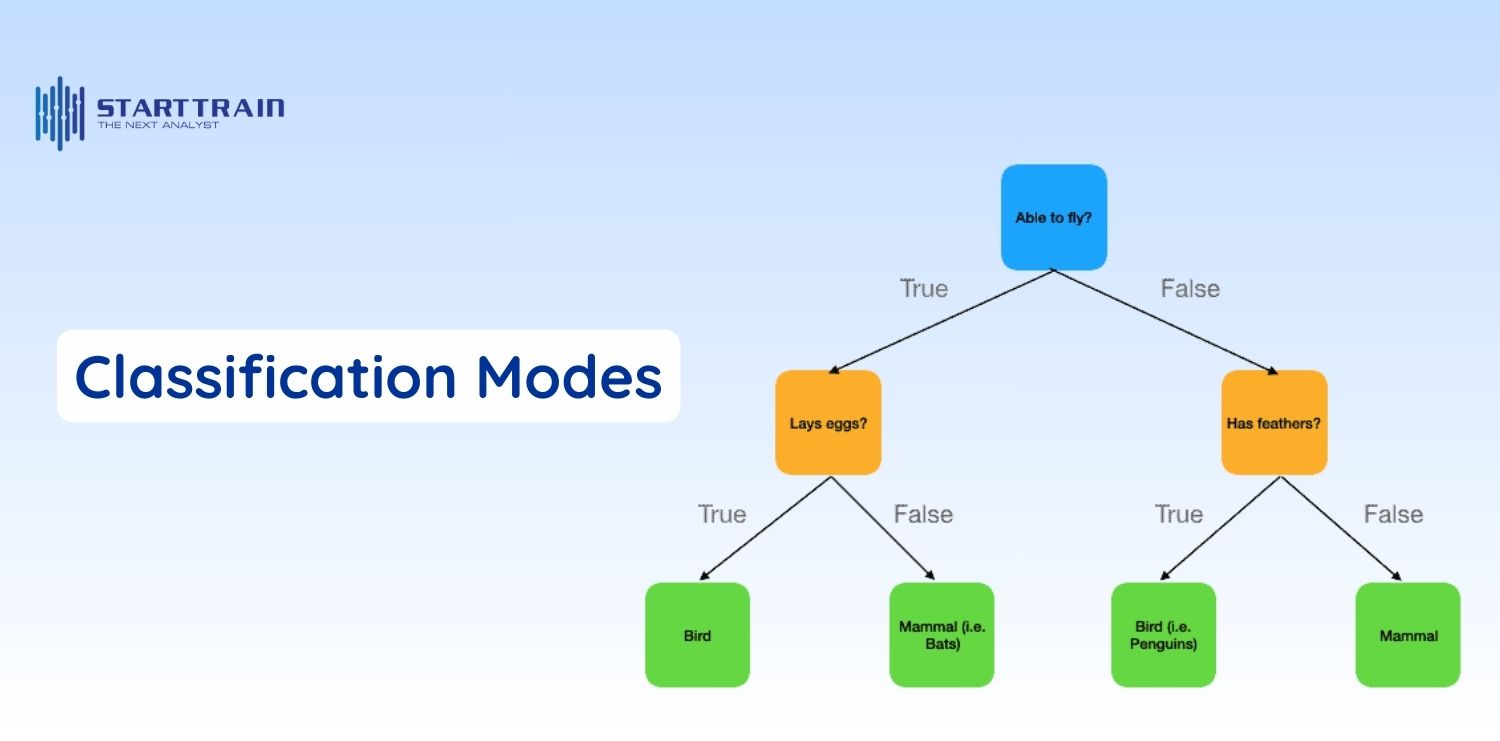
Khác với phân loại, mô hình phân cụm thuộc nhóm học máy không giám sát (unsupervised learning). Nó tự động nhóm các điểm dữ liệu dựa trên các thuộc tính tương đồng mà không cần gắn nhãn trước.
Mô hình này tập trung vào việc phân tích các đầu vào dữ liệu theo một tần suất thời gian nhất định (theo giờ, ngày, tuần, tháng…). Mục tiêu là đánh giá tính mùa vụ, xu hướng và các hành vi có tính chu kỳ của dữ liệu.

Mặc dù Predictive Analytics và Machine Learning thường được sử dụng thay thế cho nhau trong các cuộc thảo luận về dữ liệu, chúng thực sự là hai khái niệm riêng biệt nhưng có mối quan hệ cộng sinh chặt chẽ.
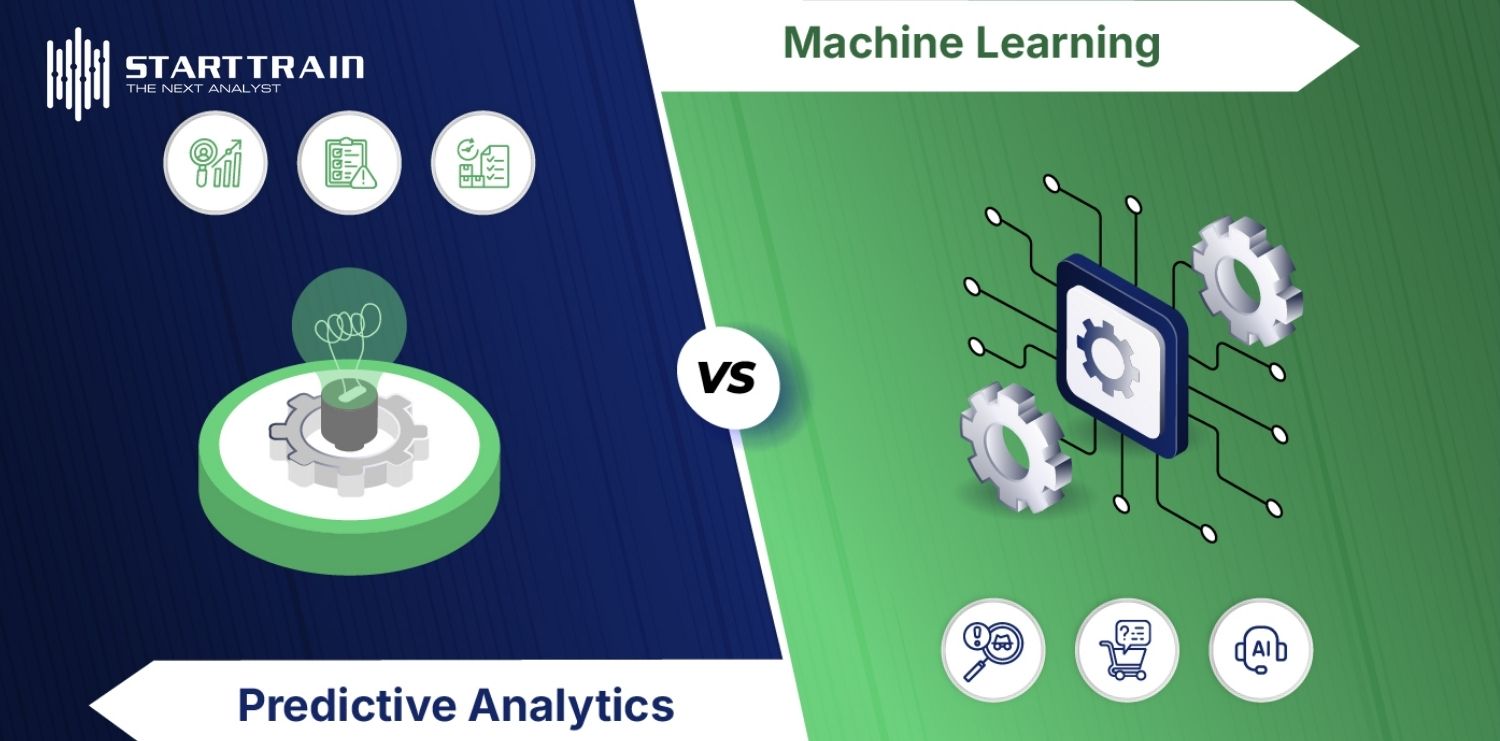
Phân tích dự đoán là một mục tiêu kinh doanh hoặc một ứng dụng phân tích cụ thể, trong khi Học máy (Machine Learning – ML) là một trong những phương pháp chính để đạt được mục tiêu đó. Predictive Analytics sử dụng các thuật toán ML như một công cụ cốt lõi để tự động hóa việc tìm kiếm các quy luật trong các tập dữ liệu lớn và phức tạp. Nếu không có ML, việc phân tích dự đoán sẽ bị giới hạn trong các phương pháp thống kê truyền thống, vốn khó có thể xử lý được khối lượng dữ liệu khổng lồ của thời đại Big Data.
Mục tiêu cuối cùng của Predictive Analytics là cung cấp một dự báo cụ thể phục vụ cho quá trình ra quyết định (ví dụ: dự đoán một giao dịch có phải gian lận hay không). Ngược lại, Machine Learning là một lĩnh vực rộng lớn thuộc Trí tuệ nhân tạo (AI), tập trung vào việc phát triển các hệ thống có khả năng tự học và cải thiện hiệu suất từ kinh nghiệm (dữ liệu) mà không cần lập trình cứng. ML không chỉ dùng cho dự đoán mà còn dùng cho nhận diện hình ảnh, xử lý ngôn ngữ tự nhiên và nhiều tác vụ tự động hóa khác.
Có thể hiểu đơn giản rằng Machine Learning là động cơ cung cấp sức mạnh tính toán và khả năng thích ứng, còn Predictive Analytics là phương tiện đưa doanh nghiệp đến đích đến là những hiểu biết về tương lai. PA tận dụng khả năng xử lý của các mô hình ML để không chỉ dừng lại ở việc trả lời “điều gì đã xảy ra” mà còn có thể tinh chỉnh các dự báo ban đầu thành những chiến lược kinh doanh có độ chính xác cao.
Chất lượng và sự đa dạng của dữ liệu đầu vào quyết định trực tiếp đến độ tin cậy của các dự báo. Để xây dựng một mô hình Predictive Analytics hoàn chỉnh, các chuyên gia thường kết hợp nhiều nhóm dữ liệu sau:
Đây là loại dữ liệu được tổ chức chặt chẽ theo các định dạng cố định, giúp máy tính dễ dàng tìm kiếm và xử lý.
Loại dữ liệu này không có định dạng định sẵn, chiếm phần lớn khối lượng thông tin mà doanh nghiệp thu thập được hiện nay.
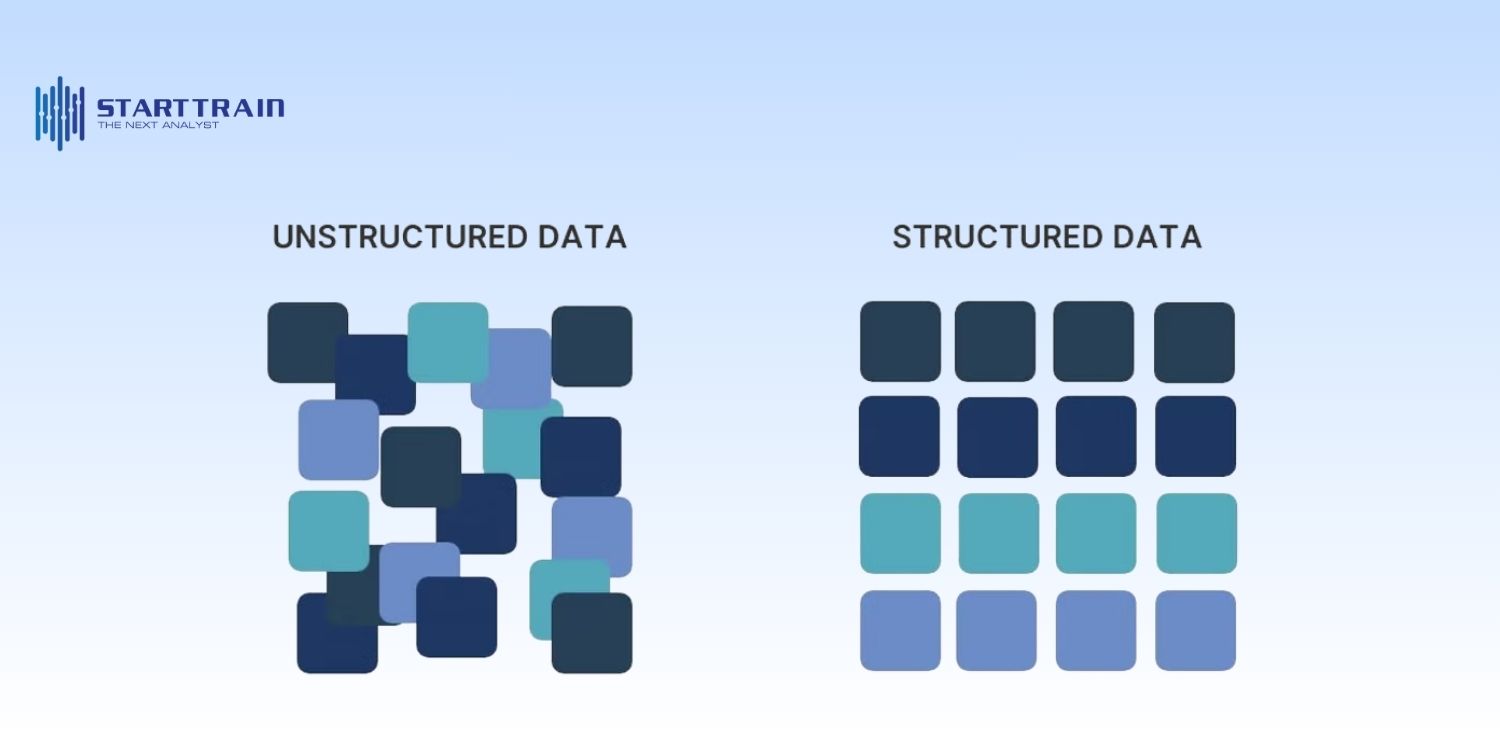
Nằm giữa hai loại trên, loại dữ liệu này không nằm trong bảng nhưng chứa các thẻ (tags) hoặc dấu hiệu để phân tách các yếu tố thông tin. Ví dụ cụ thể: Tệp JSON, XML, tệp nhật ký hệ thống (log files) hoặc các tệp siêu dữ liệu (metadata) đi kèm với email.
Phân tích dự đoán có thể được triển khai trên nhiều lĩnh vực khác nhau để giải quyết các bài toán kinh doanh cụ thể. Dưới đây là các ví dụ minh họa cách công nghệ này hỗ trợ quá trình ra quyết định trong thực tế:
Các dịch vụ tài chính sử dụng Machine Learning và các công cụ định lượng để đưa ra dự báo về khách hàng tiềm năng. Ngân hàng có thể giải quyết các câu hỏi như: Ai có khả năng vỡ nợ? Khách hàng nào có mức độ rủi ro cao hay thấp? Khách hàng nào mang lại lợi nhuận cao nhất để tập trung nguồn lực marketing? Ngoài ra, nó cũng giúp xác định các hành vi chi tiêu có dấu hiệu gian lận ngay lập tức.
Trong ngành y tế, phân tích dự đoán được dùng để phát hiện và quản lý việc chăm sóc cho các bệnh nhân mắc bệnh mãn tính, cũng như theo dõi các tình trạng nhiễm trùng cụ thể như nhiễm trùng huyết (sepsis). Ví dụ, tổ chức Geisinger Health đã khai thác hồ sơ sức khỏe của hơn 10.000 bệnh nhân từng bị nhiễm trùng huyết để xây dựng mô hình dự đoán. Kết quả thu được rất ấn tượng khi mô hình có thể dự báo chính xác những bệnh nhân có tỷ lệ sống sót cao, giúp tối ưu hóa phác đồ điều trị.
Các nhóm nhân sự sử dụng dữ liệu khảo sát nhân viên và phân tích dự đoán để sàng lọc ứng viên phù hợp, giảm tỷ lệ nhân viên nghỉ việc và tăng cường mức độ gắn kết. Sự kết hợp giữa dữ liệu định lượng và định tính cho phép doanh nghiệp giảm chi phí tuyển dụng và tăng mức độ hài lòng của nhân viên, điều này đặc biệt hữu ích trong những giai đoạn thị trường lao động biến động.
Đừng để dữ liệu ngủ yên, hãy tham gia khóa học Business Intelligence HR Analytics để làm chủ các công cụ dự báo và kỹ thuật phân tích dữ liệu nhân sự.
Thay vì chỉ dựa vào báo cáo lịch sử, phân tích dự đoán cho phép doanh nghiệp chủ động hơn trong suốt vòng đời khách hàng. Dự báo tỷ lệ rời bỏ (churn prediction) giúp đội ngũ bán hàng nhận diện những khách hàng không hài lòng sớm hơn để can thiệp kịp thời. Trong khi đó, các nhóm marketing có thể tận dụng phân tích dữ liệu cho các chiến lược bán chéo (cross-sell) thông qua các công cụ gợi ý (recommendation engines) trên website.
Doanh nghiệp sử dụng công nghệ này để quản lý hàng tồn kho và thiết lập chiến lược giá. Phân tích dự đoán giúp đáp ứng nhu cầu khách hàng mà không gây tình trạng tồn kho quá mức. Ví dụ, FleetPride đã sử dụng dữ liệu từ các đơn hàng vận chuyển trong quá khứ để lập kế hoạch chính xác hơn và đặt ra ngưỡng cung ứng phù hợp dựa trên nhu cầu thực tế của thị trường cho các linh kiện máy móc.

Predictive Analytics (Phân tích dự đoán) không còn là một lựa chọn xa xỉ mà đã trở thành công cụ sống còn giúp doanh nghiệp tồn tại trong kỷ nguyên số. Bằng cách biến những dữ liệu quá khứ thành những hiểu biết giá trị cho tương lai, tổ chức có thể chủ động lập kế hoạch, giảm thiểu rủi ro và tối đa hóa lợi nhuận. Tuy nhiên, để thành công, doanh nghiệp cần bắt đầu từ việc chuẩn hóa dữ liệu và lựa chọn các mô hình phân tích phù hợp với mục tiêu kinh doanh cốt lõi của mình.
Nếu bạn muốn bắt đầu hành trình trở thành chuyên gia dữ liệu, hãy tham khảo khóa học Business Intelligence Essentials tại Starttrain. Đây là những bước đệm hoàn hảo giúp bạn biến dữ liệu quá khứ thành những chiến lược kinh doanh đột phá cho tương lai.









