Địa chỉ:
Lầu 7 Tòa nhà STA, 618 đường 3/2, Phường Diên Hồng (Phường 14, Quận 10), TP HCM
Giờ làm việc
Thứ 2 tới thứ 6: 8:00 - 17:00
Địa chỉ:
Lầu 7 Tòa nhà STA, 618 đường 3/2, Phường Diên Hồng (Phường 14, Quận 10), TP HCM
Giờ làm việc
Thứ 2 tới thứ 6: 8:00 - 17:00
Trong kỷ nguyên của các mô hình ngôn ngữ lớn (LLM) như GPT-4, Claude 3 hay Gemini, thuật ngữ Context Window (cửa sổ ngữ cảnh) đã trở thành một trong những thông số kỹ thuật quan trọng nhất để đánh giá sức mạnh của một trí tuệ nhân tạo. Vậy thực chất Context Window là gì và tại sao nó lại quyết định mức độ thông minh của AI? Hãy cùng Starttrain tìm hiểu chi tiết trong bài viết dưới đây.
Context Window (Cửa sổ ngữ cảnh) là lượng dữ liệu tối đa (văn bản, mã code, hình ảnh, …) mà một mô hình ngôn ngữ lớn có thể xử lý và ghi nhớ tại một thời điểm nhất định trong một phiên làm việc.

Bạn có thể hình dung Context Window giống như bộ nhớ ngắn hạn của con người. Khi bạn đọc một cuốn sách, khả năng bạn nhớ được các chi tiết ở trang 1 khi đang đọc ở trang 100 chính là “cửa sổ ngữ cảnh” của bạn. Trong AI, nếu dữ liệu đầu vào vượt quá giới hạn của cửa sổ này, mô hình sẽ bắt đầu “quên” các thông tin cũ nhất để nhường chỗ cho thông tin mới, dẫn đến việc mất đi tính nhất quán hoặc hiểu sai ý đồ của người dùng.
Mỗi khi bạn tương tác với một mô hình ngôn ngữ lớn, hệ thống không chỉ đọc tin nhắn hiện tại mà còn nạp lại toàn bộ lịch sử hội thoại liên quan vào mô hình. Context Window hoạt động như một bộ nhớ tạm (working memory), khác biệt hoàn toàn với kho dữ liệu khổng lồ mà AI đã được huấn luyện từ trước. Trong khi dữ liệu huấn luyện là kiến thức tĩnh, thì cửa sổ ngữ cảnh là những gì AI thực sự biết và nhìn thấy ngay tại thời điểm đưa ra câu trả lời.
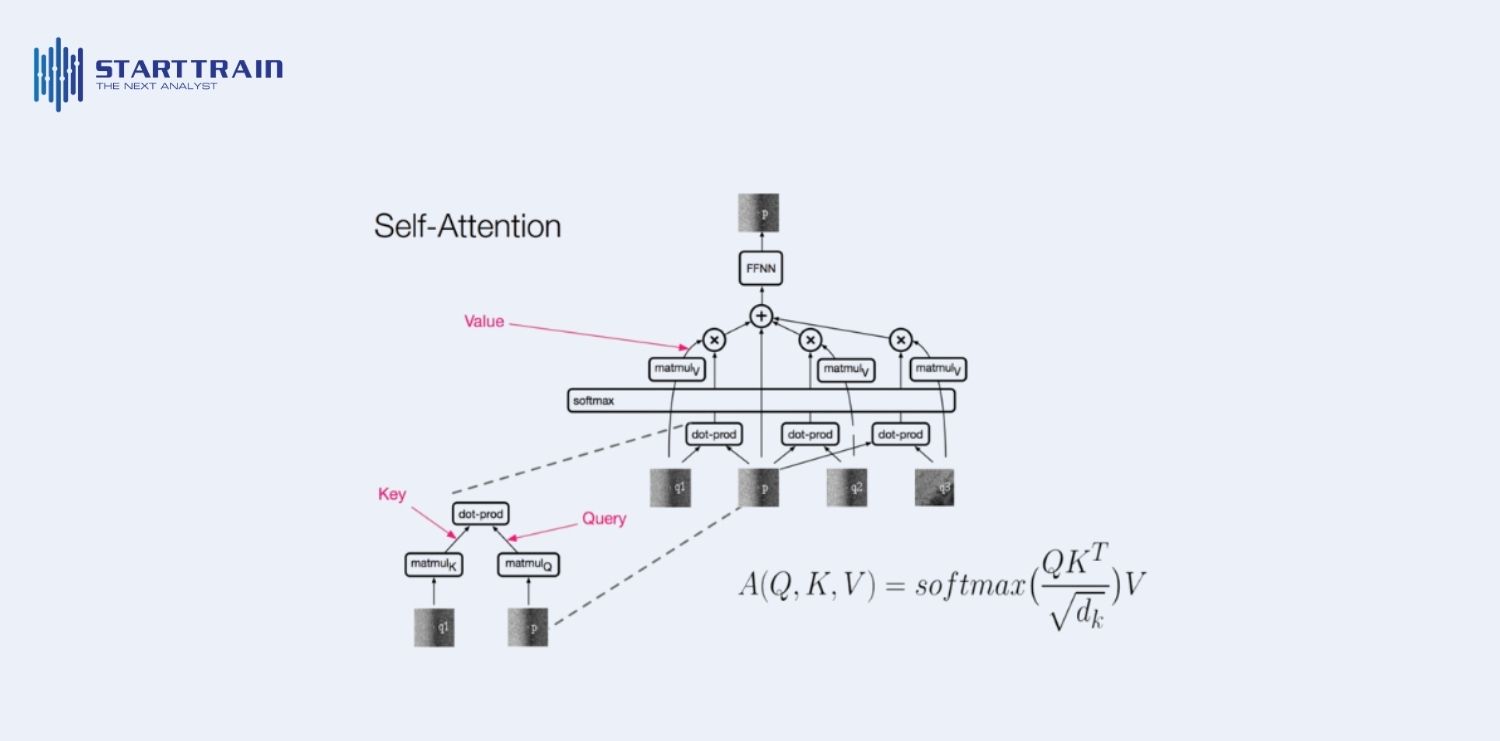
Cơ chế cốt lõi đằng sau quá trình này là Attention (Sự chú ý). Khi văn bản được đưa vào, AI không đọc từng từ tuần tự như con người mà xử lý đồng thời tất cả các token. Cơ chế Attention sẽ thực hiện các phép so sánh chéo giữa mọi token với nhau để xác định mối quan hệ ngữ nghĩa. Điều này cho phép AI duy trì sự mạch lạc trong các cuộc hội thoại dài, xem xét đồng thời nhiều tài liệu tham khảo hoặc chính sách công ty để đưa ra phản hồi chính xác nhất.

Tuy nhiên, quá trình xử lý này đòi hỏi tài nguyên tính toán cực kỳ lớn. Do cơ chế Attention so sánh mọi cặp token, chi phí tính toán sẽ tăng theo hàm bình phương của độ dài đầu vào. Ví dụ, nếu bạn tăng gấp 10 lần số lượng token (từ 1.000 lên 10.000), số phép tính cần thực hiện sẽ tăng lên gấp 100 lần (từ 1 triệu lên 100 triệu phép so sánh). Đây chính là lý do tại sao các cửa sổ ngữ cảnh lớn hơn thường đi kèm với độ trễ (latency) cao hơn và chi phí vận hành đắt đỏ hơn.
Trong các giao diện lập trình (API), cửa sổ ngữ cảnh thường tích lũy theo mô hình tịnh tiến: mỗi lượt phản hồi của AI sẽ trở thành một phần dữ liệu đầu vào cho lượt tương tác kế tiếp. Quá trình này diễn ra liên tục cho đến khi chạm mức giới hạn tối đa của mô hình. Tại thời điểm đó, để tiếp tục hội thoại, hệ thống buộc phải loại bỏ các phần dữ liệu cũ nhất (thường là theo nguyên tắc First-In, First-Out) hoặc áp dụng các kỹ thuật nén ngữ cảnh để giữ lại những thông tin quan trọng nhất.
Để hiểu về kích thước của Context Window, chúng ta không thể bỏ qua khái niệm tokenization. Cách các LLM xử lý ngôn ngữ về cơ bản khác với con người. Trong khi đơn vị nhỏ nhất chúng ta sử dụng là các ký tự (chữ cái, chữ số, dấu câu), thì AI sử dụng token. Để mô hình hiểu được, mỗi token được gán một mã số ID duy nhất; chính những mã số này mới là thứ AI thực sự xử lý.

Token đại diện cho điều gì? Không có một quy tắc cố định nào cho việc một token đại diện cho bao nhiêu văn bản. Một token có thể là một ký tự đơn lẻ, một phần của từ (tiền tố, hậu tố), một từ nguyên vẹn hoặc thậm chí là một cụm từ ngắn. Hãy xem xét vai trò của chữ “a” trong các ví dụ sau để hiểu cách tokenization hoạt động:
Tỷ lệ quy đổi và sự khác biệt ngôn ngữ Mỗi mô hình AI có một bộ mã hóa (tokenizer) khác nhau, nên không có “tỷ giá hối đoái” cố định giữa từ và token. Tuy nhiên, một ước tính phổ biến cho tiếng Anh là khoảng 1.5 token cho mỗi từ. Bạn có thể sử dụng các công cụ như Tokenizer Playground của Hugging Face để thử nghiệm cách các mô hình khác nhau chia nhỏ văn bản.
Đáng chú ý, cấu trúc ngôn ngữ ảnh hưởng lớn đến hiệu quả của tokenization. Ví dụ, một nghiên cứu vào tháng 10/2024 cho thấy cùng một câu văn, khi dịch từ tiếng Anh sang tiếng Telugu (một ngôn ngữ Ấn Độ), dù bản dịch Telugu có ít ký tự hơn nhưng lại tiêu tốn số lượng token gấp 7 lần. Điều này có nghĩa là người dùng các ngôn ngữ không phải tiếng Anh đôi khi sẽ bị “thiệt thòi” hơn về không gian trong Context Window.
Khái niệm Context Window không chỉ dành riêng cho các mô hình ngôn ngữ lớn (LLM). Bất kỳ mô hình học máy nào sử dụng kiến trúc Transformer đều phải đối mặt với giới hạn này. Nguyên nhân sâu xa nằm ở sự đánh đổi giữa khả năng xử lý và tài nguyên hệ thống.
Mô hình Transformer sử dụng cơ chế Self-attention (Tự chú ý) để tính toán mối quan hệ giữa các phần khác nhau của đầu vào (ví dụ: mối liên hệ giữa từ đầu tiên và từ cuối cùng của một đoạn văn). Về mặt toán học, AI tạo ra các vector trọng số cho mỗi token để xác định mức độ liên quan của nó với các token khác. Do mọi token đều phải so sánh với tất cả các token còn lại, nhu cầu tính toán tăng theo hàm bình phương ($O(n^2)$). Nếu số lượng token tăng gấp đôi, năng lượng xử lý cần thiết sẽ tăng gấp 4 lần.
Ít người biết rằng, nội dung bạn nhập vào không phải là thứ duy nhất chiếm chỗ trong Context Window. Có nhiều thành phần vô hình khác cũng tiêu tốn token:
Tăng kích thước cửa sổ đồng nghĩa với việc đòi hỏi lượng VRAM khổng lồ trên GPU để lưu trữ ma trận chú ý. Ngoài ra, vì các mô hình LLM hoạt động theo cơ chế tự hồi quy (autoregressive) – dự đoán từng từ một dựa trên toàn bộ các từ trước đó – nên cửa sổ càng dài, AI càng mất nhiều thời gian để “đọc lại” và suy luận, gây ra độ trễ lớn trong các phản hồi thời gian thực.
Điều thú vị là Transformer không chỉ dùng cho văn bản. Các mô hình khuếch tán (diffusion models) dùng để tạo ảnh cũng áp dụng cơ chế này. Khi đó, ngữ cảnh không phải là token mà là các pixel. Một hình ảnh có độ phân giải quá cao có thể vượt quá Context Window của mô hình do chứa quá nhiều pixel để xử lý cùng lúc.
Việc mở rộng cửa sổ ngữ cảnh không chỉ đơn thuần là tăng dung lượng chứa từ ngữ, mà nó mở ra những khả năng ứng dụng thực tế mang tính đột phá cho cả cá nhân và doanh nghiệp:
Với một cửa sổ ngữ cảnh rộng lớn, AI có thể tiếp nhận đồng thời một lượng dữ liệu khổng lồ từ nhiều nguồn khác nhau. Bạn có thể tải lên toàn bộ mã nguồn của một dự án phức tạp để tìm lỗi, hoặc đưa vào hàng nghìn trang tài liệu pháp lý để yêu cầu tóm tắt. Đặc biệt, các mô hình hiện đại cho phép kết hợp đa phương thức: người dùng có thể tải lên hàng giờ video, các tệp âm thanh ghi âm cuộc họp và hàng trăm hình ảnh để AI phân tích và dự thảo báo cáo tổng hợp chỉ trong vài phút.
Cửa sổ ngữ cảnh dài giúp giảm bớt các công đoạn chuẩn bị dữ liệu bên ngoài mô hình. Thay vì phải tốn thời gian chia nhỏ file hoặc chọn lọc thủ công các đoạn văn bản quan trọng (như khi sử dụng các mô hình cửa sổ ngắn), người dùng có thể nạp trực tiếp toàn bộ dữ liệu gốc. Điều này giúp các nhà phát triển phần mềm nhanh chóng hiểu rõ cấu trúc của các codebase cũ hoặc giúp các nhà phân tích thị trường khai thác hiểu biết từ mọi đánh giá của khách hàng trong một khoảng thời gian dài mà không bỏ sót bất kỳ chi tiết nhỏ nào.
Thay vì phải trải qua quá trình huấn luyện lại (fine-tuning) tốn kém và phức tạp, người dùng có thể tận dụng Context Window dài để dạy AI ngay trong câu lệnh. Bằng cách cung cấp hàng trăm ví dụ về phong cách viết, định dạng báo cáo hoặc quy trình xử lý tình huống đặc thù của doanh nghiệp, AI có thể mô phỏng chính xác các yêu cầu này ngay lập tức. Khả năng duy trì sự nhất quán qua các cuộc hội thoại kéo dài nhiều ngày cũng giúp AI trở thành một trợ lý thực thụ, luôn “nhớ” rõ các chi tiết nhỏ đã thảo luận từ trước.

Mặc dù mang lại lợi ích khổng lồ, việc sở hữu và vận hành các mô hình có Context Window siêu lớn vẫn phải đối mặt với những rào cản kỹ thuật và kinh tế đáng kể:
Thách thức lớn nhất nằm ở chi phí tài nguyên. Do nhu cầu tính toán tăng theo hàm bình phương của độ dài đầu vào, việc xử lý một cửa sổ ngữ cảnh lớn đòi hỏi hệ thống GPU cực kỳ mạnh mẽ và tiêu tốn nhiều năng lượng. Điều này dẫn đến hai hệ lụy trực tiếp cho người dùng: chi phí cho mỗi câu lệnh (query) trở nên đắt đỏ hơn và thời gian phản hồi (latency) chậm đi đáng kể. Đối với các ứng dụng yêu cầu phản hồi tức thì trong thời gian thực, việc sử dụng cửa sổ ngữ cảnh quá lớn đôi khi không phải là lựa chọn tối ưu.
Các nghiên cứu khoa học đã chỉ ra rằng các mô hình ngôn ngữ thường có xu hướng chú ý nhiều hơn đến thông tin ở đầu hoặc cuối câu lệnh, trong khi dễ dàng bỏ sót các chi tiết nằm ở giữa đoạn văn bản dài. Khi lượng token tăng lên đến mức hàng trăm nghìn hoặc hàng triệu, độ chính xác trong việc truy hồi thông tin (recall) sẽ bị suy giảm.
Hiện tượng này, cùng với “context rot” (sự suy giảm tính nhất quán khi ngữ cảnh quá nhiễu), có thể khiến AI đưa ra các câu trả lời nghe có vẻ thuyết phục nhưng thực chất lại thiếu chính xác hoặc bỏ sót những dữ kiện then chốt.
Khi nạp một lượng dữ liệu quá lớn vào AI, con người dần mất đi khả năng kiểm soát và giải thích (explainability) về cách mô hình đưa ra kết quả. Việc xác định xem AI dựa trên đoạn văn bản nào trong hàng triệu dòng dữ liệu để đưa ra kết luận trở nên cực kỳ khó khăn. Điều này gây ra những rủi ro về tính tin cậy, đặc biệt là trong các lĩnh vực nhạy cảm như y tế hoặc luật pháp, nơi mà mỗi quyết định của AI cần phải được truy xuất nguồn gốc một cách rõ ràng và minh bạch.

Context Window không chỉ là một con số kỹ thuật, nó là giới hạn của trí tưởng tượng và khả năng giải quyết vấn đề của AI. Dù cửa sổ ngữ cảnh dài không phải là “viên đạn bạc” giải quyết mọi vấn đề, nhưng nó là công cụ mạnh mẽ giúp các doanh nghiệp tăng tốc đổi mới. Trong tương lai, khi các rào cản về phần cứng và thuật toán được gỡ bỏ, chúng ta có thể kỳ vọng vào những hệ thống AI có khả năng ghi nhớ và phân tích dữ liệu gần như vô hạn.







